在C语言中最好使用#define 或者 const 以付符号代表数字常量
scanf 的输入会自动跳过空格,在某些特定的输入在遇到上一次的输入中残留的空格或者是空格则要清空缓存区,可以用getchar();
字符串常量用双引号引起来的字符串表示
strlen可以获取一个字符串的长度 也可以用 sizeof()
4.8
7题
#include<stdio.h>
#include<float.h>
int main()
{
double a=1.0/3.0;
float b=1.0/3.0;
printf("%.4lf %.12lf %.16lf\n",a,a,a);
printf("%.4f %.12f %.16f\n",b,b,b);
printf("%d\n",FLT_DIG);
printf("%d\n",DBL_DIG);
return 0;
}8题
#include<stdio.h>
#define a 3.785
#define b 1.609
int main()
{
float n,m;
float q,w;
q=m*a;
w=n*b;
printf("请输入行驶的英里数和消耗汽油的加仑数:\n");
scanf("%f %f\n",&n,&m);
printf("消耗每加仑行驶的英里数是:%.1f\n",n/m);
printf("每一百公里消耗:%.1f",(w/q)*100);
return 0;
}5.2基本运算符
5.2.1 “=”
这个“=”并不意味着相等,而是赋值,把右值赋给左值
但是如果定义了#define 或者 const 的变量只可以做右值
golf.c
#include <stdio.h>
int main(void)
{
int jane, tarzan, cheeta;
cheeta = tarzan = jane = 68;
printf(" cheeta tarzan jane\n");
printf("First round score %4d %8d %8d\n", cheeta, tarzan,jane);
return 0;
}5.2.2 “+”
加法运算,相加的可以是常量也可以是变量
5.2.3 “-”
减法运算,同上,两者都被称为二元运算符,也即需要两个运算对象才能完成操作
5.2.4 “-和+”
这个是符号运算符
5.2.5 “*“
乘法运算
平方表
#include <stdio.h>
int main(void)
{
int num = 1;
while (num < 21)
{
printf("%4d %6d\n", num, num * num);
num = num + 1;
}
return 0;
}指数增长
#include <stdio.h>
#define SQUARES 64
int main(void)
{
const double CROP = 2E16;
double current, total;
int count = 1;
printf("square grains total ");
printf("fraction of \n");
printf(" added grains ");
printf("world total\n");
total = current = 1.0;
printf("%4d %13.2e %12.2e %12.2e\n", count, current,total, total / CROP);
while (count < SQUARES)
{
count = count + 1;
current = 2.0 * current;
total = total + current;
printf("%4d %13.2e %12.2e %12.2e\n", count, current,total, total / CROP);
}
printf("That's all.\n");
return 0;
}5.2.6 ”/“
除法运算
左侧是被除数,右侧是除数
整数的除法和浮点数的除法不一样,浮点数除法的结果是浮点数,整数的结果是整数,整数没有小数部分,会自动省率小数部分,这一过程被称为截断
divide.c
#include <stdio.h>
int main(void)
{
printf("integer division: 5/4 is %d \n", 5 / 4);
printf("integer division: 6/3 is %d \n", 6 / 3);
printf("integer division: 7/4 is %d \n", 7 / 4);
printf("floating division: 7./4. is %1.2f \n", 7. / 4.);
printf("mixed division: 7./4 is %1.2f \n", 7. / 4);
return 0;
}5.2.7 运算优先级
常用运算与数学相同
5.2.8优先级和求值顺序
rules.c
#include <stdio.h>
int main(void)
{
int top, score;
top = score = -(2 + 5) * 6 + (4 + 3 * (2 + 3));
printf("top = %d, score = %d\n", top, score);
return 0;
}5.3其他运算符
5.3.1 sizeof 和 size_t
sizeof运算符是以字节为单位返回运算对象的大小,对象可以是具体的数据对象(变量名)或类型,如果运算的是类型则要括起来(float)
sizeof.c程序
#include <stdio.h>
int main(void)
{
int n = 0;
size_t intsize;
intsize = sizeof (int);
printf("n = %d, n has %zd bytes; all ints have %zd
bytes.\n",n, sizeof n, intsize);
return 0;
}sizeof返回的 size_t 这种无符号的整数类型
(C99新增 %zd 用于printf()显示size_t类型的值,如果不支持c99也可以用%u %lu %zd代替)
5.3.2 求模运算符 ”%“
求模运算符用于整数运算。求模运算符给出其左侧 整数除以右侧整数的余数
求模运算符常用于控制程序流。例如,假设你正在设计一个账单预 263 算程序,每 3 个月要加进一笔额外的费用。这种情况可以在程序中对月份求 模3(即,month % 3),并检查结果是否为0。 如果为0,便加进额外的费 用。
min_scc.c程序
#include <stdio.h>
#define SEC_PER_MIN 60 // 1分钟60秒
int main(void)
{
int sec, min, left;
printf("Convert seconds to minutes and seconds!\n");
printf("Enter the number of seconds (<=0 to quit):\n");
scanf("%d", &sec); // 读取秒数
while (sec > 0)
{
min = sec / SEC_PER_MIN; // 截断分钟数
left = sec % SEC_PER_MIN; // 剩下的秒数
printf("%d seconds is %d minutes, %d seconds.\n", sec,min, left);
printf("Enter next value (<=0 to quit):\n");
scanf("%d", &sec);
}
printf("Done!\n");
return 0;
}
负数求模
如果第1个运算对象是负数,那么求模的结 果为负数;如果第1个运算对象是正数,那么求模的结果也是正数
11 / 5得2,11 % 5得1 11 / -5得-2,11 % -2得1 -11 / -5得2,-11 % -5得-1 -11 / 5得-2,-11 % 5得-1 (c99规定的趋零截断)
标准规 定:无论何种情况,只要a和b都是整数值,便可通过a - (a/b)*b来计算a%b
5.3.3 递增运算符 ”++“
两种方式一种++在变量之前,一种在变量之后,两者运算时间不同
例如:add_one.c程序
#include <stdio.h>
int main(void)
{
int ultra = 0, super = 0;
while (super < 5)
{
super++;
++ultra;
printf("super = %d, ultra = %d \n", super, ultra);
}
return 0;
}
前缀是先递增,再运算,后缀是先运算在递增
5.3.4 递减运算符 ”-“
同上
bottles.c程序
#include <stdio.h>
#define MAX 100
int main(void)
{
int count = MAX + 1;
while (--count > 0)
{
printf("%d bottles of spring water on the wall, "
"%d bottles of spring water!\n", count, count);
printf("Take one down and pass it around,\n");
printf("%d bottles of spring water!\n\n", count - 1);
}
return 0;
}
5.3.5 优先级
递增运算符和递减运算符都有很高的结合优先级,只有圆括号的优先级 比它们高
x*y++表示的是(x)(y++),而不是(x+y)++
如果n++是表达式的一部分,可将其视为“先使用n,再递增”;而++n则 表示“先递增n,再使用”。
5.3.6 不要自作聪明
如果一个变量出现在一个函数的多个参数中,不要对该变量使用递增或 递减运算符; 如果一个变量多次出现在一个表达式中,不要对该变量使用递增或递减 运算符。 另一方面,对于何时执行递增,C 还是做了一些保证。我们在本章后面 的“副作用和序列点”中学到序列点时再来讨论这部分内容。
5.4 表达式和语句
5.4.1 表达式
表达式(expression)由运算符和运算对象组成
简单的表达式是一个单独的运算对象,以此为 基础可以建立复杂的表达式
运算对象可以是常量、变量或二者的组合。一些表达式由子 表达式(subexpression)组成(子表达式即较小的表达式)。例如,c/d是上 面例子中a*(b + c/d)/20的子表达式。
***每个表达式都有一个值 ***
C 表达式的一个最重要的特性是,每个表达式都有一个值。要获得这个 值,必须根据运算符优先级规定的顺序来执行操作。
5.4.2 语句
一条语句相当于一条完整的 计算机指令 。大部分的语句都是以分号作为结尾的,比如 legd=4 这就是一个表达式,如果加上分号就是一个语句
赋值表达式语句在程序中很常用:它为变量分配一个值。赋值表达式语 句的结构是,一个变量名,后面是一个赋值运算符,再跟着一个表达式,最 后以分号结尾。
函数表达式语句会引起函数调用。
C语言的术语副作用(side effect)。副作用是对数据对 象或文件的修改。
states = 50; 它的副作用是将变量的值设置为50。
序列点(sequence point)是程序执行的点,在该点上,所有的副作用都 在进入下一步之前发生。
***在 C语言中,语句中的分号标记了一个序列点。 ***
y = (4 + x++) + (6 + x++); 表达式4 + x++不是一个完整的表达式,所以C无法保证x在子表达式4 + x++求值后立即递增x。这里,完整表达式是整个赋值表达式语句,分号标记 了序列点。所以,C 保证程序在执行下一条语句之前递增x两次。C并未指明 是在对子表达式求值以后递增x,还是对所有表达式求值后再递增x。因此, 要尽量避免编写类似的语句。
5.4.3 复合语句 (块)
复合语句(compound statement)是用花括号括起来的一条或多条语句, 复合语句也称为块(block)
5.5 类型转换
在语句和表达式中应使用类型相同的变量和常量。但是,如果使 用混合类型,C 不会像 Pascal那样停在那里死掉,而是采用一套规则进行自 动类型转换。
转换规则
1.
当类型转换出现在表达式时,无论是unsigned还是signed的char和short 都会被自动转换成int,如有必要会被转换成unsigned int(如果short与int的大 小相同,unsigned short就比int大。这种情况下,unsigned short会被转换成 unsigned int)。在K&R那时的C中,float会被自动转换成double(目前的C不 是这样)。由于都是从较小类型转换为较大类型,所以这些转换被称为升级 (promotion)。
2.
涉及两种类型的运算,两个值会被分别转换成两种类型的更高级别。
3.
3.类型的级别从高至低依次是long double、double、float、unsignedlong long、long long、unsigned long、long、unsigned int、int。例外的情况是,当 long 和 int 的大小相同时,unsigned int比long的级别高。之所以short和char类 型没有列出,是因为它们已经被升级到int或unsigned int。
4.
在赋值表达式语句中,计算的最终结果会被转换成被赋值变量的类 型。这个过程可能导致类型升级或降级(demotion)。所谓降级,是指把一 种类型转换成更低级别的类型。
5.
当作为函数参数传递时,char和short被转换成int,float被转换成 double。
类型升级通常都不会有什么问题,但是类型降级会导致真正的麻烦。原 因很简单:较低类型可能放不下整个数字。
如果待转换的值与目标类型不匹配怎么办?这取决于转换涉及的类型。 待赋值的值与目标类型不匹配时,规则如下。
1.目标类型是无符号整型,且待赋的值是整数时,额外的位将被忽略。 例如,如果目标类型是 8 位unsigned char,待赋的值是原始值求模256。 2.如果目标类型是一个有符号整型,且待赋的值是整数,结果因实现而 异。 3.如果目标类型是一个整型,且待赋的值是浮点数,该行为是未定义 的。
如果把一个浮点值转换成整数类型会怎样?当浮点类型被降级为整数类 型时,原来的浮点值会被截断。
5.5.1 强制类型转换运算符
通常,应该避免自动类型转换,尤其是类型降级。但是如果能小心使 用,类型转换也很方便。我们前面讨论的类型转换都是自动完成的。然而, 有时需要进行精确的类型转换,或者在程序中表明类型转换的意图。这种情 况下要用到强制类型转换(cast),即在某个量的前面放置用圆括号括起来 的类型名,该类型名即是希望转换成的目标类型。圆括号和它括起来的类型 名构成了强制类型转换运算符(cast operator),其通用形式是: (type) 用实际需要的类型(如,long)替换type即可。
赋值运算符: = 将其右侧的值赋给左侧的变量 算术运算符: + 将其左侧的值与右侧的值相加 - 将其左侧的值减去右侧的值 - 作为一元运算符,改变其右侧值的符号 * 将其左侧的值乘以右侧的值 / 将其左侧的值除以右侧的值,如果两数都是整数,计算结果 将被截断 % 当其左侧的值除以右侧的值时,取其余数(只能应用于整 数) 291 ++ 对其右侧的值加1(前缀模式),或对其左侧的值加1(后缀 模式) – 对其右侧的值减1(前缀模式),或对其左侧的值减1(后缀模 式) 其他运算符: sizeof 获得其右侧运算对象的大小(以字节为单位),运算对象 可以是一个被圆括号括起来的类型说明符,如sizeof(float),或者是一个具体 的变量名、数组名等,如sizeof foo (类型名) 强制类型转换运算符将其右侧的值转换成圆括号中指定 的类型,如(float)9把整数9转换成浮点数9.0
控制语句:循环
6.1while 循环
summing.c程序
#include <stdio.h>
int main(void)
{
long num;
long sum = 0l; /* 把sum初始化为0 */
int status;
printf("Please enter an integer to be summed ");
printf("(q to quit): ");
status = scanf("%ld", &num);
while (status == 1) /* == 的意思是“等于” */
{
sum = sum + num;
printf("Please enter next integer (q to quit): ");
status = scanf("%ld", &num);
}
printf("Those integers sum to %ld.\n", sum);
return 0;
}
该程序使用long类型以储存更大的整数。尽管C编译器会把0自动转换为 合适的类型,但是为了保持程序的一致性,我们把sum初始化为 ***0L(long类 型的0),而不是0(int类型的0)。 ***
6.1.1 程序注释
因为while循环是入口条件循环,程序在进入循环体之前必须获 取输入的数据并检查status的值,所以在 while 前面要有一个 scanf()。要让循 环继续执行,在循环内需要一个读取数据的语句,这样程序才能获取下一个 status的值,所以在while循环末尾还要有一个scanf(),它为下一次迭代做好 了准备。可以把下面的伪代码作为while循环的标准格式: 获得第1个用于测试的值 当测试为真时 处理值 获取下一个值
6.1.2 C风格读取循环
status = scanf(“%ld”, &num);
while (status == 1) {
status = scanf(“%ld”, &num);
}
可以用这些代码替换:** while (scanf(“%ld”, &num) == 1) **{ /循环行为/ } 第二种形式同时使用scanf()的两种不同的特性。
首先,如果函数调用成 功,scanf()会把一个值存入num。然后,利用scanf()的返回值(0或1,不是 num的值)控制while循环。因为每次迭代都会判断循环的条件,所以每次迭 代都要调用scanf()读取新的num值来做判断。换句话说,C的语法特性让你可 以用下面的精简版本替换标准版本: 当获取值和判断值都成功 处理该值
6.2 while 语句
while循环的通用形式如下:
while(条件)
语句
statement部分可以是以分号结尾的简单语句,也可以是用花括号括起来 的复合语句。
6.2.1 终止while循环
while循环有一点非常重要:在构建while循环时,必须让测试表达式的 值有变化,表达式最终要为假。否则,循环就不会终止不过可以使用 break和if语句来终止循环
6.2.2 何时终止循环
只有在对测试条件求值时,才决定是终止还是继续循环。
when.c程序
#include <stdio.h>
int main(void)
{
int n = 5;
while (n < 7)
{
printf("n = %d\n", n);
n++;
printf("Now n = %d\n", n);
}
printf("The loop has finished.\n");
return 0;
}
6.2.3 while: 入口条件循环
while循环是使用入口条件的有条件循环。所谓“有条件”指的是语句部 分的执行取决于测试表达式描述的条件,如(index < 5)。该表达式是一个入 口条件(entry condition),因为必须满足条件才能进入循环体。在下面的情 况中,就不会进入循环体,因为条件一开始就为假:
6.2.4 语法要点
使用while时,要牢记一点:只有在测试条件后面的单独语句(简单语 句或复合语句)才是循环部分。
while.c程序
#include <stdio.h>
int main(void)
{
int n = 0;
while (n++ < 3); //空循环
printf("n is %d\n", n); /* 第8行 */
printf("That's all this program does.\n");
return 0;
}
6.3 用关系运算符和表达式比较大小
while循环经常依赖测试表达式作比较,这样的表达式被称为关系表达 式(relational expression),出现在关系表达式中间的运算符叫做关系运算 符(relational operator)。
使用fabs()函数(声明在math.h头文件中) 可以方便地比较浮点数,该函数返回一个浮点值的绝对值(即,没有代数符 号的值)。
fabs实例
#include <math.h>
#include <stdio.h>
int main(void)
{
const double ANSWER = 3.14159;
double response;
printf("What is the value of pi?\n");
scanf("%lf", &response);
while (fabs(response - ANSWER) > 0.0001)
{
printf("Try again!\n");
scanf("%lf", &response);
}
printf("Close enough!\n");
return 0;
}
6.3.1 什么是真
对C而言,表达式为真的值是1,表达式为假的值是0。
6.3.2 其他真值
只要测试条件的值为非零,就会执行 while 循环。这是从数 值方面而不是从真/假方面来看测试条件。要牢记:关系表达式为真,求值 得1;关系表达式为假,求值得0。因此,这些表达式实际上相当于数值。 许多C程序员都会很好地利用测试条件的这一特性。例如,用while (goats)替换while (goats !=0),因为表达式goats != 0和goats都只有在goats的值 为0时才为0或假。第1种形式(while (goats != 0))对初学者而言可能比较清 楚,但是第2种形式(while (goats))才是C程序员最常用的。
6.3.3 真值的问题
不要在本应使用==的地方使用=。一些计算机语言(如,BASIC)用相 同的符号表示赋值运算符和关系相等运算符,但是这两个运算符完全不同 。赋值运算符把一个值赋给它左侧的变量;而关系相等运算符 检查它左侧和右侧的值是否相等,不会改变左侧变量的值(如果左侧是一个 变量)。
6.3.4 新的_Bool类型
在编程中,表示真或假的变 量被称为布尔变量(Boolean variable),所以_Bool是C语言中布尔变量的类 型名。_Bool类型的变量只能储存1(真)或0(假)。如果把其他非零数值 赋给_Bool类型的变量,该变量会被设置为1。这反映了C把所有的非零值都 视为真。
C99提供了stdbool.h头文件,该头文件让bool成为_Bool的别名,而且还 把true和false分别定义为1和0的符号常量。包含该头文件后,写出的代码可 以与C++兼容,因为C++把bool、true和false定义为关键字
6.3.5 优先级和关系运算符
关系运算符的优先级比算术运算符(包括+和-)低,比赋值运算符高。 这意味着x > y + 2和x > (y+ 2)相同,x = y > 2和x = (y > 2)相同。换言之,如 果y大于2,则给x赋值1,否则赋值0。y的值不会赋给x。
关系运算符比赋值运算符的优先级高,因此,x_bigger = x > y;相当于 x_bigger = (x > y);。
关系运算符之间有两种不同的优先级。
高优先级组: <<= >>=
低优先级组: == !=
与其他大多数运算符一样,关系运算符的结合律也是从左往右。
6.4 不确定循环和计数循环
一些while循环是不确定循环(indefinite loop)。所谓不确定循环,指 在测试表达式为假之前,预先不知道要执行多少次循环。
在创建一个重复执行固定次数的循环中涉及了3个行为:
1.必须初始化计数器;
2.计数器与有限的值作比较;
3.每次循环时递增计数器。
while循环的测试条件执行比较,递增运算符执行递增。 ,递增发生在循环的末尾,这可以防止不小心漏掉递增
6.5 for 循环
关键字for后面的圆括号中有3个表达式,分别用两个分号隔开。第1个 表达式是初始化,只会在for循环开始时执行一次。第 2 个表达式是测试条 件,在执行循环之前对表达式求值。如果表达式为假(本例中,count大于 NUMBER时),循环结束。第3个表达式执行更新,在每次循环结束时求 值。程序清单6.10用这个表达式递增count 的值,更新计数。完整的for语句 还包括后面的简单语句或复合语句。for圆括号中的表达式也叫做控制表达 式,它们都是完整表达式,所以每个表达式的副作用(如,递增变量)都发 生在对下一个表达式求值之前。
6.5.1 利用for的灵活性
第1个表 达式给计数器赋初值,第2个表达式表示计数器的范围,第3个表达式递增计 数器。
用法
- 可以使用递减运算符来递减计数器
- 可以让计数器递增2、10等
- 可以用字符代替数字计数
- 可以让递增的量几何增长,而不是算术增长。也就是说,每次都乘上而 不是加上一个固定的量
- 可以省略一个或多个表达式(但是不能省略分号),只要在循环中包含 能结束循环的语句即可。
- 第1个表达式不一定是给变量赋初值,也可以使用printf()。在执 行循环的其他部分之前,只对第1个表达式求值一次或执行一次。
for语句使用3个表达式控制循环过程,分别用分号隔开。initialize表达 式在执行for语句之前只执行一次;然后对test表达式求值,如果表达式为真 (或非零),执行循环一次;接着对update表达式求值,并再次检查test表达 式。for语句是一种入口条件循环,即在执行循环之前就决定了是否执行循 环。因此,for循环可能一次都不执行。statement部分可以是一条简单语句或 复合语句。
形式:
for ( initialize; test; update )
statement
在test为假或0之前,重复执行statement部分。
作业
6.编写一个程序打印一个表格,每一行打印一个整数、该数的平方、该 数的立方。要求用户输入表格的上下限。使用一个for循环。
#include <stdio.h>
int main(void)
{
int a,b;
printf("请输入上下限:");
scanf("%d %d",&a,&b);
for (a;a<=b;a++)
{
printf("%-5d %-5d %-5d \n",a,a*a,a*a*a);
}
return 0;
}
6.6 其他赋值运算符 +=,-=,*=,/=,%=
C有许多赋值运算符。最基本、最常用的是=,它把右侧表达式的值赋 给左侧的变量。其他赋值运算符都用于更新变量,其用法都是左侧是一个变 量名,右侧是一个表达式。赋给变量的新值是根据右侧表达式的值调整后的 值。确切的调整方案取决于具体的运算符
x *= 3 * y + 12 与 x = x * (3 * y + 12) 相同
6.7 逗号运算符
逗号运算符扩展了for循环的灵活性,以便在循环头中包含更多的表达 式。
逗号运算符并不局限于在for循环中使用,但是这是它最常用的地方。 逗号运算符有两个其他性质。首先,它保证了被它分隔的表达式从左往右求 值(换言之,逗号是一个序列点,所以逗号左侧项的所有副作用都在程序执 行逗号右侧项之前发生)。
逗号运算符把两个表达式连接成一个表达式,并保证最左边的表达式最 先求值。逗号运算符通常在for循环头的表达式中用于包含更多的信息。整 个逗号表达式的值是逗号右侧表达式的值。
6.8 出口条件循环 :do while
while循环和for循环都是入口条件循环,即在循环的每次迭代之前检查 测试条件,所以有可能根本不执行循环体中的内容。C语言还有出口条件循 环(exit-condition loop),即在循环的每次迭代之后检查测试条件,这保证 了至少执行循环体中的内容一次。这种循环被称为 do while循环。
do while循环的通用形式:
do
statement
while ( expression );
statement可以是一条简单语句或复合语句。注意,do while循环以分号 结尾
do while 语句创建一个循环,在 expression 为假或 0 之前重复执行循环 体中的内容。do while语句是一种出口条件循环,即在执行完循环体后才根 据测试条件决定是否再次执行循环。因此,该循环至少必须执行一次。 statement部分可是一条简单语句或复合语句。
6.10 嵌套循环
嵌套循环(nested loop)指在一个循环内包含另一个循环。嵌套循环常 用于按行和列显示数据,也就是说,一个循环处理一行中的所有列,另一个 循环处理所有的行。
作业:9*9乘法表
#include<stdio.h>
int main()
{
int a,b;
for (a=1;a<=9;a++)
{
for (b=1;b<=a;b++)
{
printf("%d*%d=%-3d",b,a,a*b);
}
printf("\n");
}
return 0;
}
7.1 if 语句
实列程序分析
#include <stdio.h>
int main(void)
{
const int FREEZING = 0;
float temperature;
int cold_days = 0;
int all_days = 0;
printf("Enter the list of daily low temperatures.\n");
printf("Use Celsius, and enter q to quit.\n");
while (scanf("%f", &temperature) == 1)
{
all_days++;
if (temperature < FREEZING)
cold_days++;
}
if (all_days != 0)
printf("%d days total: %.1f%% were below freezing.\n",
all_days, 100.0 * (float) cold_days / all_days);
if (all_days == 0)
printf("No data entered!\n");
return 0;
}
while循环的测试条件利用scanf()的返回值来结束循环,因为scanf()在读 到非数字字符时会返回0。temperature的类型是float而不是int,这样程序既可 以接受-2.5这样的值,也可以接受8这样的值。
if 语句指示计算机,如果刚读取的值(remperature)小于 0,就把 cold_days 递增 1;如果temperature不小于0,就跳过cold_days++;语句,while 循环继续读取下一个温度值。
接着,该程序又使用了两次if语句控制程序的输出。如果有数据,就打 印结果;如果没有数据,就打印一条消息(稍后将介绍一种更好的方法来处 理这种情况)。
为避免整数除法,该程序示例把计算后的百分比强制转换为 float类 型。其实,也不必使用强制类型转换,因为在表达式100.0 * cold_days / all_days中,将首先对表达式100.0 * cold_days求值,由于C的自动转换类型 规则,乘积会被强制转换成浮点数。但是,使用强制类型转换可以明确表达 转换类型的意图,保护程序免受不同版本编译器的影响。if语句被称为分支 语句(branching statement)或选择语句(selection statement),因为它相当 于一个交叉点,程序要在两条分支中选择一条执行。
if语句的通用形式如 下:
if ( expression )
statement
如果对expression求值为真(非0),则执行statement;否则,跳过 statement。与while循环一样,statement可以是一条简单语句或复合语句。if 语句的结构和while语句很相似,它们的主要区别是:如果满足条件可执行 的话,if语句只能测试和执行一次,而while语句可以测试和执行多次。
通常,expression 是关系表达式,即比较两个量的大小(如,表达式 x > y 或 c == 6)。如果expression为真(即x大于y,或c == 6),则执行 statement。否则,忽略statement。概括地说,可以使用任意表达式,表达式 的值为0则为假。
7.2 if else语句
7.2.1 介绍getchar() putchar()
getchar()函数不带任何参数,它从输入队列中返回下一个字符。例如, 下面的语句读取下一个字符输入,并把该字符的值赋给变量ch:
ch = getchar();
该语句与下面的语句效果相同:
scanf(“%c”, &ch);
putchar()函数打印它的参数。
例如,下面的语句把之前赋给ch的值作为 字符打印出来:
putchar(ch); 该语句与下面的语句效果相同:
printf(“%c”, ch);
由于这些函数只处理字符,所以它们比更通用的scanf()和printf()函数更 快、更简洁。而且,注意 getchar()和 putchar()不需要转换说明,因为它们只 处理字符。这两个函数通常定义在 stdio.h头文件中
7.2.2 ctyoe.h系列的字符函数
。C 有一系列专门处理字符的函数,ctype.h头文件包含了这些 函数的原型。这些函数接受一个字符作为参数,如果该字符属于某特殊的类 别,就返回一个非零值(真);否则,返回0(假)。例如,如果isalpha() 函数的参数是一个字母,则返回一个非零值。
实例
#include <stdio.h>
#include <ctype.h> // 包含isalpha()的函数原型
int main(void)
{
char ch;
while ((ch = getchar()) != '\n')
{
if (isalpha(ch)) // 如果是一个字符,
putchar(ch + 1); // 显示该字符的下一个字符
else // 否则,
putchar(ch); // 原样显示
}
putchar(ch); // 显示换行符
return 0;
}
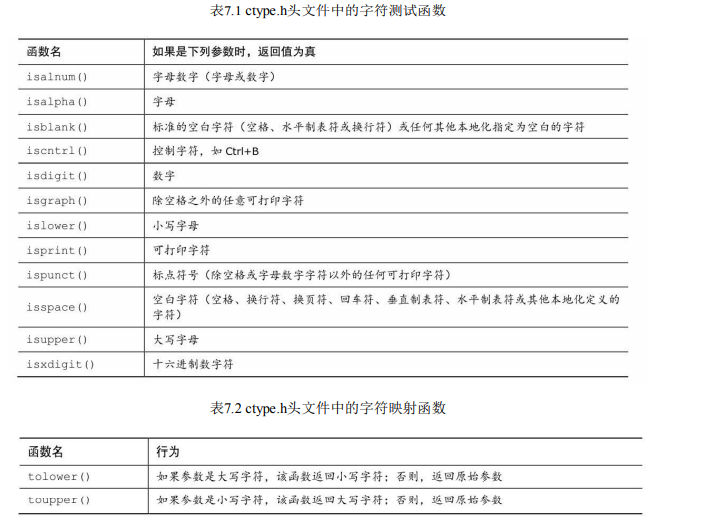
。有些函数涉及本地 化,指的是为适应特定区域的使用习惯修改或扩展 C 基本用法的工具(例 如,许多国家在书写小数点时,用逗号代替点号,于是特殊的本地化可以指 定C编译器使用逗号以相同的方式输出浮点数,这样123.45可以显示为 123,45)。注意,字符映射函数不会修改原始的参数,这些函数只会返回已 修改的值。也就是说,下面的语句不改变ch的值:
tolower(ch); // 不影响ch的值
这样做才会改变ch的值:
ch = tolower(ch); // 把ch转换成小写字母
7.2.3 多重选择 else if
在程序中也可以用else if扩展if else结 构模拟这种情况。
实际上,else if 是已学过的 if else 语句的变式。例如,该程序的核心部 分只不过是下面代码的另一种写法:
也就是说,该程序由一个ifelse语句组成,else部分包含另一个if else语 句,该if else语句的else部分又包含另一个if else语句。第2个if else语句嵌套 在第 1个if else语句中,第3个if else语句嵌套在第2个if else语句中。回忆一 下,整个if else语句被视为一条语句,因此不必把嵌套的if else语句用花括号 括起来。当然,花括号可以更清楚地表明这种特殊格式的含义。
这两种形式完全等价。唯一不同的是使用空格和换行的位置不同,不过 编译器会忽略这些。
7.2.4 else 与if 的配对
规则是,如果没有花括号,else与离它最近的if匹配,除非最近的if被花 括号括起来
作业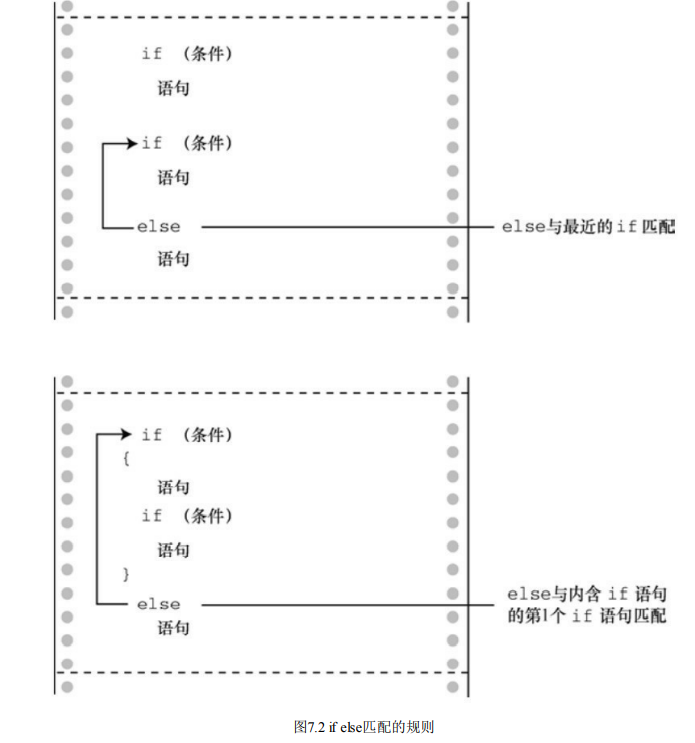
.编写一个程序,提示用户输入一周工作的小时数,然后打印工资总 额、税金和净收入。做如下假设: a.基本工资 = 1000美元/小时 b.加班(超过40小时) = 1.5倍的时间 c.税率: 前300美元为15% 续150美元为20% 余下的为25% 用#define定义符号常量。
#include <stdio.h>
#define wage 10
#define xianzhi 40
#define chaoguo 1.5
#define a 300
#define b 150
#define rate1 0.15
#define rate2 0.20
#define rate3 0.25
int main(void)
{
int hour;
double money,tax,qian;
printf("请输入一周工作时间:");
scanf("%d", &hour);
if (hour <= xianzhi)
money = hour * wage;
else
money = xianzhi * wage + (hour - xianzhi) * wage* chaoguo;
if (money <= a)
tax = money* rate1;
else if (money <= a + b)
tax = a * rate1 + (money - a) * rate2;
else
tax = a * rate1 + rate2 * rate2 + (money - a - b) * rate3;
qian = money - tax;
printf("money: %.2f tax: %.2f qian: %.2f\n", money, tax, qian);
return 0;
}
7.2.5 多层嵌套的if语句
在编写程序的代码之前要先规划好。首先,要总体设计一下程序。为方 便起见,程序应该使用一个循环让用户能连续输入待测试的数。这样,测试 一个新的数字时不必每次都要重新运行程序。
从技术角度看,if else语句作为一条单独的语句,不必使用花括号。外 层if也是一条单独的语句,也不必使用花括号。但是,当语句太长时,使用 花括号能提高代码的可读性,而且还可防止今后在if循环中添加其他语句时 忘记加花括号。
一直以来,C都习惯用int作为标记的类型,其实新增的_Bool类型更合 适。
用if语句进行选择
形式1:
if (expression)
statement
如果expression为真,则执行statement部分。
形式2:
if (expression)
statemen
else
statement2
形式3:
if (expression1)
statement1
else if (expression2)
statement2
else
statement3
如果expression1为真,执行statement1部分;如果expression2为真,执行 statement2部分;否则,执行statement3部分。
7.3 逻辑运算符
if 语句和 while 语句通常使用关系表达式作为测试 条件。有时,把多个关系表达式组合起来会很有用
逻辑运算符两侧的条件必须都为真,整个表达式才为真。逻辑运算符的 优先级比关系运算符低*,所以不必在子表达式两侧加圆括号。
&& 与
|| 或
!非
7.3.1 iso646.h头文件
C 是在美国用标准美式键盘开发的语言。但是在世界各地,并非所有的 键盘都有和美式键盘一样的符号。因此,C99标准新增了可代替逻辑运算符 的拼写,它们被定义在ios646.h头文件中。如果在程序中包含该头文件,便 可用and代替&&、or代替||、not代替!
7.3.2 优先级
!运算符的优先级很高,比乘法运算符还高,与递增运算符的优先级相 同,只比圆括号的优先级低。&&运算符的优先级比||运算符高,但是两者的 优先级都比关系运算符低,比赋值运算符高。因此,表达式a >b && b > c || b > d相当于((a > b) && (b > c)) || (b > d)。
7.3.3 求值顺序
除了两个运算符共享一个运算对象的情况外,C 通常不保证先对复杂表 达式中哪部分求值。
逻辑表达式的求值顺序是从左往右。一旦发现有使整个表达式为假的因 素,立即停止求值。
7.3.4范围
&&运算符可用于测试范围。
if (90 <= range <= 100) // 千万不要这样写!
这样写的问题是代码有语义错误,而不是语法错误,所以编译器不会捕 获这样的问题(虽然可能会给出警告)。由于<=运算符的求值顺序是从左 往右,所以编译器把测试表达式解释为:
7.4 一个统计单词的程序
首先,该程序要逐个字符读取输入,知道何时停止读取。然后,该程序 能识别并计算这些内容:字符、行数和单词。据此我们编写的伪代码如下:
读取一个字符
当有多输入时
递增字符计数
如果读完一行,递增行数计数
如果读完一个单词,递增单词计数
读取下一个字符
前面有一个输入循环的模型
while ((ch = getchar()) != STOP)
{
……..
}
这里,STOP表示能标识输入末尾的某个值。以前我们用过换行符和句 点标记输入的末尾,但是对于一个通用的统计单词程序,它们都不合适。我 们暂时选用一个文本中不常用的字符(如,|)作为输入的末尾标记。
现在,我们考虑循环体。因为该程序使用getchar()进行输入,所以每次 迭代都要通过递增计数器来计数。为了统计行数,程序要能检查换行字符。 如果输入的字符是一个换行符,该程序应该递增行数计数器。这里要注意 STOP 字符位于一行的中间的情况。是否递增行数计数?我们可以作为特殊 行计数,即没有换行符的一行字符。可以通过记录之前读取的字符识别这种 情况,即如果读取时发现 STOP 字符的上一个字符不是换行符,那么这行就 是特殊行。
最棘手的部分是识别单词。首先,必须定义什么是该程序识别的单词。 我们用一个相对简单的方法,把一个单词定义为一个不含空白(即,没有空 格、制表符或换行符)的字符序列。因此,“glymxck”和“r2d2”都算是一个单 词。
判断非空白字符最直接的测试表达式是:
c != ‘ ‘ && c != ‘\n’ && c != ‘\t’ /* 如果c不是空白字符,该表达式为真* /
检测空白字符最直接的测试表达式是:
c == ‘ ‘ || c == ‘\n’ || c == ‘\t’ /如果c是空白字符,该表达式为真/
然而,使用ctype.h头文件中的函数isspace()更简单,如果该函数的参数 是空白字符,则返回真。所以,如果c是空白字符,isspace(c)为真;如果c不 是空白字符,!isspace(c)为真。
程序清单.wordcnt.c程序
#include <stdio.h>
#include <ctype.h> // 为isspace()函数提供原型
#include <stdbool.h> // 为bool、true、false提供定义
#define STOP '|'
int main(void)
{
char c; // 读入字符
char prev; // 读入的前一个字符
long n_chars = 0L;// 字符数
int n_lines = 0; // 行数
int n_words = 0; // 单词数
int p_lines = 0; // 不完整的行数
bool inword = false; // 如果c在单词中,inword 等于 true
printf("Enter text to be analyzed (| to terminate):\n");
prev = '\n'; // 用于识别完整的行
while ((c = getchar()) != STOP)
{
n_chars++; // 统计字符
if (c == '\n')
n_lines++; // 统计行
if (!isspace(c) && !inword)
{
inword = true;// 开始一个新的单词
n_words++; // 统计单词
}
if (isspace(c) && inword)
inword = false; // 打到单词的末尾
prev = c; // 保存字符的值
}
if (prev != '\n')
p_lines = 1;
printf("characters = %ld, words = %d, lines = %d, ",
n_chars, n_words, n_lines);
printf("partial lines = %d\n", p_lines);
return 0;
}
作业
判断输入年份是否为闰年
#include <stdio.h>
int main()
{
int year,a;
printf("请输人年份:\n");
scanf("%d",&year);
if(year%400==0)
a=1;
else
{
if(year%4==0&&year%100!=0)
a=1;
else
a=0;
}
if(a==1)
{
printf("这是闰年\n");
}
else
{
printf("这不是闰年\n");
}
return 0;
}
7.5 条件运算符: ?:
C提供条件表达式(conditional expression)作为表达if else语句的一种 便捷方式,该表达式使用?:条件运算符。
该运算符分为两部分,需要 3 个运 算对象。
带一个运算对象的运算符称为一元运算符,带两个运算 对象的运算符称为二元运算符。
带 3 个运算对象的运算符称为三 元运算符。条件运算符是C语言中唯一的三元运算符。下
x = (y < 0) ? -y : y; 绝对值运算
在=和;之间的内容就是条件表达式,该语句的意思是“如果y小于0,那 么x = -y;否则,x = y”。
用if else可以这样表达:
if (y < 0)
x = -y;
else x = y;
条件表达式的通用形式如下: expression1 ? expression2 : expression3
如果 expression1 为真(非 0),那么整个条件表达式的值与 expression2 的值相同;如果expression1为假(0),那么整个条件表达式的值与 expression3的值相同。
7.6 辅助循环 continue 和 break
continue 和break语句可以根据循环体中的测试结果来忽略一部 分循环内容,甚至结束循环。
7.6.1 continue 语句
执行到该语句时,会跳过本次迭代的 剩余部分,并开始下一轮迭代。如果continue语句在嵌套循环内,则只会影 响包含该语句的内层循环。
使用continue的好处是减少主语句组中的一级缩进。当语 句很长或嵌套较多时,紧凑简洁的格式提高了代码的可读性。
了continue语句让程序跳过循环体的余下部分。那么,从何处 开始继续循环?对于while和 do while 循环,执行 continue 语句后的下一个 行为是对循环的测试表达式求值。
7.6.2 break 语句
程序执行到循环中的break语句时,会终止包含它的循环,并继续执行 下一阶段。
break还可用于因其他原因退出循环的情况。
在for循环中的break和continue的情况不同,执行完break语句后会直接执 行循环后面的第1条语句,连更新部分也跳过。嵌套循环内层的break只会让程序跳出包含它的当前循环,要跳出外层循环还需要一个break:
7.7 多重选择: switch 和 break
使用条件运算符和 if else 语句很容易编写二选一的程序。然而,有时程 序需要在多个选项中进行选择。可以用if else if…else来完成。但是,大多数 情况下使用switch语句更方便
7.7.1 switch 语句
要对紧跟在关键字 switch 后圆括号中的表达式求值。然后程序扫描标签,到发现一个匹配的值为止。然后程序跳转至那一行。 如果没有匹配的标签怎么办?如果有default :标签行,就跳转至该行;否 则,程序继续执行在switch后面的语句。
break语句在其中起什么作用?它让程序离开switch语句,跳至switch语 句后面的下一条语句。如果没有break语句,就会从匹配标签开 始执行到switch末尾。例
break语句可用于循环和switch语句中,但是continue只能用 于循环中。尽管如此,如果switch语句在一个循环中,continue便可作为 switch语句的一部分。这种情况下,就像在其他循环中一样,continue让程序 跳出循环的剩余部分,包括switch语句的其他部分。
switch在圆括号中的测试表达式的值应该是一个整数值(包括char类 型)。case标签必须是整数类型(包括char类型)的常量或整型常量表达式 (即,表达式中只包含整型常量)。不能用变量作为case标签。
switch的构造如下
switch ( 整型表达式)
{ case 常量1:
语句 <–可选
case 常量2:
语句 <–可选
default : <–可选
语句 <–可选
}
7.7.2 只读每行的首字符
丢弃 一行中其他字符的行为,经常出现在响应单字符的交互程序中。可以用下面 的代码实现这样的行为:
while (getchar() != ‘\n’)
continue; /* 跳过输入行的其余部分 */
循环从输入中读取字符,包括按下Enter键产生的换行符。注意,函数 的返回值并没有赋给ch,以上代码所做的只是读取并丢弃字符。由于最后丢 弃的字符是换行符,所以下一个被读取的字符是下一行的首字母。在外层的 while循环中,getchar()读取首字母并赋给ch。
假设用户一开始就按下Enter键,那么程序读到的首个字符就是换行 符。下面的代码处理这种情况:
if (ch == ‘\n’)
continue;
7.7.3 多重标签
可以在switch语句中使用多重case标签。
实例
#include <stdio.h>
int main(void)
{
char ch;
int a_ct, e_ct, i_ct, o_ct, u_ct;
a_ct = e_ct = i_ct = o_ct = u_ct = 0;
printf("Enter some text; enter # to quit.\n");
while ((ch = getchar()) != '#')
{
switch (ch)
{
case 'a':
case 'A': a_ct++;
break;
case 'e':
case 'E': e_ct++;
break;
case 'i':
case 'I': i_ct++;
break;
case 'o':
case 'O': o_ct++;
break;
case 'u':
case 'U': u_ct++;
break;
default: break;
} // switch结束
} // while循环结束
printf("number of vowels: A E I O U\n");
printf(" %4d %4d %4d %4d %4d\n",
a_ct, e_ct, i_ct, o_ct, u_ct);
return 0;
}
假设如果ch是字母i,switch语句会定位到标签为case ‘i’ :的位置。由于 该标签没有关联break语句,所以程序流直接执行下一条语句,即i_ct++;。 如果 ch是字母I,程序流会直接定位到case ‘I’ :。本质上,两个标签都指的是 相同的语句。
严格地说,case ‘U’的 break 语句并不需要。因为即使删除这条 break 语 句,程序流会接着执行switch中的下一条语句,即default : break;。所以,可 以把case ‘U’的break语句去掉以缩短代码。但是从另一方面看,保留这条 break语句可以防止以后在添加新的case(例如,把y作为元音)时遗漏break 语句。
在该例中,如果使用ctype.h系列的toupper()函数(参见表7.2)可以避免 使用多重标签,在进行测试之前就把字母转换成大写字母:
ch = toupper(ch);
或者,也可以先不转换ch,把toupper(ch)放进switch的测试条件中: switch(toupper(ch))。
7.7.4 switch 和if else
何时使用switch?何时使用if else?你经常会别无选择。如果是根据浮 点类型的变量或表达式来选择,就无法使用 switch。如果根据变量在某范围 内决定程序流的去向,使用 switch 就很麻烦,这种情况用if就很方便:
使用switch要涵盖以上范围,需要为每个整数(3~999)设置case标 签。但是,如果使用switch,程序通常运行快一些,生成的代码少一些。
作业
ABC 邮购杂货店出售的洋蓟售价为 2.05 美元/磅,甜菜售价为 1.15 美元/磅,胡萝卜售价为 1.09美元/磅。在添加运费之前,100美元的订单有 5%的打折优惠。少于或等于5磅的订单收取6.5美元的运费和包装费,5磅~ 20磅的订单收取14美元的运费和包装费,超过20磅的订单在14美元的基础上 每续重1磅增加0.5美元。编写一个程序,在循环中用switch语句实现用户输 入不同的字母时有不同的响应,即输入a的响应是让用户输入洋蓟的磅数,b 是甜菜的磅数,c是胡萝卜的磅数,q 是退出订购。程序要记录累计的重 量。即,如果用户输入 4 磅的甜菜,然后输入 5磅的甜菜,程序应报告9磅 的甜菜。然后,该程序要计算货物总价、折扣(如果有的话)、运费和包装 费。随后,程序应显示所有的购买信息:物品售价、订购的重量(单位: 磅)、订购的蔬菜费用、订单的总费用、折扣(如果有的话)、运费和包装 费,以及所有的费用总额。
#include <stdio.h>
#define y 2.05
#define t 1.15
#define h 1.09
int main()
{
char ch;
float yang,tian,hu,sum,yunfei,money,p;
float a=0,i=0,u=0;
printf("按下 a 输入洋蓟的磅数\n按下 b 输入甜菜的磅数\n按下 c 输入胡萝卜的磅数\n按下q退出订购\n");
while ((ch = getchar()) != 'q')//要多加一个小括号,后面的优先级比较高
{
switch (ch)
{
case 'a':
printf("输入洋蓟的磅数:");
scanf("%f",&yang);
yang+=a;
printf("已购入%.2f磅洋蓟\n",yang);
break;
case 'b':
printf("输入甜菜的磅数:");
scanf("%f",&tian);
tian+=i;
printf("已购入%.2f磅甜菜\n",tian);
break;
case 'c':
printf("输入胡萝卜的磅数:");
scanf("%f",&hu);
hu+=u;
printf("已购入%.2f磅胡萝卜\n",hu);
break;
}
a=yang;
i=tian;
u=hu;
}
money=yang*y+tian*t+hu*h;
p=money;
if (money>100)
{
money=money*0.95;
}
sum=yang+tian+hu;
if (sum<=5)
{
yunfei=6.5;
}else if (sum>5 && sum<=20)
{
yunfei=14;
}else if (sum>20)
{
yunfei=14+(sum-20)*0.5;
}
printf("洋蓟售价为 2.05 美元/磅\n");
printf("甜菜售价为 1.15美元/磅\n");
printf("胡萝卜售价为 1.09美元/磅\n");
printf("总订购重量为%.2f\n",sum);
printf("订购蔬菜费用为%.2f\n",money);
printf("包装费用为%.2f\n",yunfei);
if (money>100)
{
printf("已为您折扣%.2f\n",p*0.05);
}else
{
printf("您暂无优惠\n");
}
printf("订单总费用为%.2f\n",money+yunfei);
return 0;
}
编程练习
1.
修改练习7的假设a,让程序可以给出一个供选择的工资等级菜单。使 用switch完成工资等级选择。运行程序后,显示的菜单应该类似这样: ***************************************************************** Enter the number corresponding to the desired pay rate or action: 1) $8.75/hr 2) $9.33/hr 3) $10.00/hr 4) $11.20/hr 5) quit ***************************************************************** 如果选择 1~4 其中的一个数字,程序应该询问用户工作的小时数。程 序要通过循环运行,除非用户输入 5。如果输入 1~5 以外的数字,程序应 提醒用户输入正确的选项,然后再重复显示菜单提示用户输入。使用#define 创建符号常量表示各工资等级和税率。
#include <stdio.h>
#define xianzhi 40
#define chaoguo 1.5
#define a 300
#define b 150
#define rate1 0.15
#define rate2 0.20
#define rate3 0.25
#define one 8.75
#define two 9.33
#define three 10.00
#define four 11.20
int main(void)
{
printf("*****************************************************************\n");
printf("Enter the number corresponding to the desired pay rate or action:\n");
printf("1) $8.75/hr 2) $9.33/hr\n");
printf("3) $10.00/hr 4) $11.20/hr\n");
printf("5) quit\n*****************************************************************\n");
int hour;
char this;
double wage;
double money,tax,qian;
while ((this=getchar())!='5')
{
switch (this)
{
case '1' :
wage=one;
break;
case '2' :
wage=two;
break;
case '3' :
wage=three;
break;
case '4' :
wage=four;
break;
case '5' :
break;
}
}
printf("请输入时长:");
scanf("%d", &hour);
if (hour <= xianzhi)
money = hour * wage;
else
money = xianzhi * wage + (hour - xianzhi) * wage* chaoguo;
if (money <= a)
tax = money* rate1;
else if (money <= a + b)
tax = a * rate1 + (money - a) * rate2;
else
tax = a * rate1 + rate2 * rate2 + (money - a - b) * rate3;
qian = money - tax;
printf("money: %.2f tax: %.2f qian: %.2f\n", money, tax, qian);
return 0;
}
2
#include<stdio.h>
#define dan 17850
#define hu 23900
#define gong 29750
#define li 14875
int main()
{
printf("请选择您的身份:\na:单身 b:户主\nc:已婚共有 d:已婚离异\n");
char ch;
int tax;
float wage;
while (ch=getchar()!='#')
{
switch (ch)
{
case 'a':
tax=dan;
break;
case 'b':
tax=hu;
break;
case 'c':
tax=gong;
break;
case 'd':
tax=li;
break;
}
printf("请输入您的工资:\n");
scanf("%f",&wage);
printf("您应缴税%.2f\n",0.15*tax+0.28*(wage-tax));
printf("您仍可以继续计算,输入#以结束输入,如仍需计算");
}
return 0;
}
第八章
8.1 getchar() 和 putchar()
getchar()和 putchar()每次只处理一个字符。你可能认 为这种方法实在太笨拙了,毕竟与我们的阅读方式相差甚远。但是,这种方 法很适合计算机。而且,这是绝大多数文本(即,普通文字)处理程序所用 的核心方法。
8.2 缓冲区
为什么要有缓冲区?首先,把若干字符作为一个块进行传输比逐个发送 这些字符节约时间。其次,如果用户打错字符,可以直接通过键盘修正错误。当最后按下Enter键时,传输的是正确的输入。
虽然缓冲输入好处很多,但是某些交互式程序也需要无缓冲输入。例 如,在游戏中,你希望按下一个键就执行相应的指令。因此,缓冲输入和无 缓冲输入都有用武之地。
缓冲分为两类:完全缓冲I/O和行缓冲I/O。完全缓冲输入指的是当缓冲 区被填满时才刷新缓冲区(内容被发送至目的地),通常出现在文件输入 中。缓冲区的大小取决于系统,常见的大小是 512 字节和 4096字节。行缓 冲I/O指的是在出现换行符时刷新缓冲区。键盘输入通常是行缓冲输入,所 以在按下Enter键后才刷新缓冲区。
C决定把缓冲输入作为标准的原因是:一些计算机不允许无缓冲 输入。如果你的计算机允许无缓冲输入,那么你所用的C编译器很可能会提 供一个无缓冲输入的选项。例如,许多IBM PC兼容机的编译器都为支持无 缓冲输入提供一系列特殊的函数,其原型都在conio.h头文件中。这些函数包 括用于回显无缓冲输入的getche()函数和用于无回显无缓冲输入的getch()函数 (回显输入意味着用户输入的字符直接显示在屏幕上,无回显输入意味着击 键后对应的字符不显示)。UNIX系统使用另一种不同的方式控制缓冲。在 UNIX系统中,可以使用ioctl()函数(该函数属于UNIX库,但是不属于C标 准)指定待输入的类型,然后用getchar()执行相应的操作。在ANSI C中,用 setbuf()和setvbuf()函数(详见第13章)控制缓冲,但是受限于一些系统的内 部设置,这些函数可能不起作用。总之,ANSI没有提供调用无缓冲输入的 标准方式,这意味着是否能进行无缓冲输入取决于计算机系统。
8.3 结束键盘输入
#也是一个普通的字符,有时不可避免要用 到。应该用一个在文本中用不到的字符来标记输入完成,这样的字符不会无 意间出现在输入中,在你不希望结束程序的时候终止程序。
8.3.1 文件,流和键盘输入
文件(file)是存储器中储存信息的区域。通常,文件都保存在某种永 久存储器中(如,硬盘、U盘或DVD等)。毫无疑问,文件对于计算机系统 相当重要。例如,你编写的C程序就保存在文件中,用来编译C程序的程序 也保存在文件中。后者说明,某些程序需要访问指定的文件。当编译储存在 名为 echo.c 文件中的程序时,编译器打开echo.c文件并读取其中的内容。当 编译器处理完后,会关闭该文件。其他程序,例如文字处理器,不仅要打 开、读取和关闭文件,还要把数据写入文件。
C可以使用主机操作系统的基本文件工具直接处 理文件,这些直接调用操作系统的函数被称为底层 I/O
从概念上看,C程序处理的是流而不是直接处理文件。流(stream)是 一个实际输入或输出映射的理想化数据流。这意味着不同属性和不同种类的 输入,由属性更统一的流来表示。于是,打开文件的过程就是把流与文件相 关联,而且读写都通过流来完成。
8.3.2 文件结尾
计算机操作系统要以某种方式判断文件的开始和结束。检测文件结尾的 一种方法是,在文件末尾放一个特殊的字符标记文件结尾。
在C语言中,用 getchar()读取文件检测到文件结尾时将返回一个特殊的值,即EOF(end of file的缩写)。scanf()函数检测到文件结尾时也返回EOF。通常, EOF定义 在stdio.h文件中:
#define EOF (-1)
为什么是-1?因为getchar()函数的返回值通常都介于0~127,这些值对 应标准字符集。但是,如果系统能识别扩展字符集,该函数的返回值可能在 0~255之间。无论哪种情况,-1都不对应任何字符,所以,该值可用于标记 文件结尾。
- **while ((ch = getchar()) != EOF) *** 文件输入结束标志
变量ch的类型从char变为int,因为char类型的变量只能表示0~255的无 符号整数,但是EOF的值是-1。还好,getchar()函数实际返回值的类型是 int,所以它可以读取EOF字符。如果实现使用有符号的char类型,也可以把 ch声明为char类型,但最好还是用更通用的形式
每次按下Enter键,系统便会处理缓冲区中储存的字符,并在下一行打 印该输入行的副本。这个过程一直持续到以UNIX风格模拟文件结尾(按下Ctrl+D)。在PC中,要按下Ctrl+Z。
8.4 重定向和文件
C程序使用标准I/O包查找标准输入作为输入源。这就是 前面介绍过的stdin流,它是把数据读入计算机的常用方式。它可以是一个过 时的设备,如磁带、穿孔卡或电传打印机,或者(假设)是键盘,甚至是一 些先进技术,如语音输入。
8.5 创建更友好的用户界面
8.5.1 使用缓冲输入
缓冲输入用起来比较方便,因为在把输入发送给程序之前,用户可以编 辑输入。但是,在使用输入的字符时,它也会给程序员带来麻烦。前面示例 中看到的问题是,缓冲输入要求用户按下Enter键发送输入。这一动作也传 送了换行符,程序必须妥善处理这个麻烦的换行符。
使用getchar()或者 fflush(stdin);
8.5.2 混合数值和字符输入
假设程序要求用 getchar()处理字符输入,用 scanf()处理数值输入,这两 个函数都能很好地完成任务,但是不能把它们混用。因为 getchar()读取每个 字符,包括空格、制表符和换行符;而 scanf()在读取数字时则会跳过空格、 制表符和换行符。
8.6 输入验证
scanf(“%ld”, &n) == 1
这个验证的是scanf的返回值真否为真,应用判断输入为非负数,且只有在输入整数的时候为真
while (scanf(“%ld”, &n) == 1 && n >= 0) while循环条件可以描述为“当输入是一个整数且该整数为正时”。
示例程序
#include <stdio.h>
#include <stdbool.h>
// 验证输入是一个整数
long get_long(void);
// 验证范围的上下限是否有效
bool bad_limits(long begin, long end,
long low, long high);
// 计算a~b之间的整数平方和
double sum_squares(long a, long b);
int main(void)
{
const long MIN = -10000000L; // 范围的下限
const long MAX = +10000000L; // 范围的上限
long start; // 用户指定的范围最小值
long stop; // 用户指定的范围最大值
double answer;
printf("This program computes the sum of the squares of "
"integers in a range.\nThe lower bound should not "
"be less than -10000000 and\nthe upper bound "
"should not be more than +10000000.\nEnter the "
"limits (enter 0 for both limits to quit):\n"
"lower limit: ");
start = get_long();
printf("upper limit: ");
stop = get_long();
while (start != 0 || stop != 0)
{
if (bad_limits(start, stop, MIN, MAX))
printf("Please try again.\n");
else
{
answer = sum_squares(start, stop);
printf("The sum of the squares of the integers ");
printf("from %ld to %ld is %g\n",
start, stop, answer);
}
printf("Enter the limits (enter 0 for both "
"limits to quit):\n");
printf("lower limit: ");
start = get_long();
printf("upper limit: ");
stop = get_long();
}
printf("Done.\n");
return 0;
}
long get_long(void)
{
long input;
char ch;
while (scanf("%ld", &input) != 1)
{
while ((ch = getchar()) != '\n')
putchar(ch); // 处理错误输入
printf(" is not an integer.\nPlease enter an ");
printf("integer value, such as 25, -178, or 3: ");
}
return input;
}
double sum_squares(long a, long b)
{
double total = 0;
long i;
for (i = a; i <= b; i++)
total += (double) i * (double) i;
return total;
}
bool bad_limits(long begin, long end,long low, long high)
{
bool not_good = false;
if (begin > end)
{
printf("%ld isn't smaller than %ld.\n", begin, end);
not_good = true;
}
if (begin < low || end < low)
{
printf("Values must be %ld or greater.\n", low);
not_good = true;
}
if (begin > high || end > high)
{
printf("Values must be %ld or less.\n", high);
not_good = true;
}
return not_good;
}
8.6.1 分析程序
程序遵循模块化的编程思想,使用独立函数(模块)来验证输入和管理 显示。程序越大,使用模块化编程就越重要。
main()函数管理程序流,为其他函数委派任务。它使用 get_long()获取 值、while 循环处理值、badlimits()函数检查值是否有效、sum_squres()函数 处理实际的计算:
8.6.2 输入流和数字
在编写处理错误输入的代码时(如程序清单8.7),应该很清楚C是如何 处理输入的。考虑下面的输入: ***is 28 12.4 ***
在我们眼中,这就像是一个由字符、整数和浮点数组成的字符串。但是 对 C程序而言,这是一个字节流。第1个字节是字母i的字符编码,第2个字 节是字母s的字符编码,第3个字节是空格字符的字符编码,第4个字节是数 字2的字符编码,等等。所以,如果get_long()函数处理这一行输入,第1个 字符是非数字,那么整行输入都会被丢弃,包括其中的数字,因为这些数字 只是该输入行中的其他字符:
虽然输入流由字符组成,但是也可以设置scanf()函数把它们转换成数 值。例如,考虑下面的输入:42
如果在scanf()函数中使用%c转换说明,它只会读取字符4并将其储存在 char类型的变量中。如果使用%s转换说明,它会读取字符4和字符2这两个字 符,并将其储存在字符数组中。如果使用%d转换说明,scanf()同样会读取 两个字符,但是随后会计算出它们对应的整数值:4×10+2,即42,然后将 表示该整数的二进制数储存在 int 类型的变量中。如果使用%f 转换说明,scanf()也会读取两个字符,计算出它们对应的数值42.0,用内部的浮点表示 法表示该值,并将结果储存在float类型的变量中。
简而言之,输入由字符组成,但是scanf()可以把输入转换成整数值或浮 点数值。使用转换说明(如%d或%f)限制了可接受输入的字符类型,而 getchar()和使用%c的scanf()接受所有的字符。
8.7 菜单游览
8.7.1 任务
菜单程序需要执行的任务:
- 获取用户的 响应,根据响应选择要执行的动作。
- 程序应该提供返回菜单的选项。 C 的 switch 语句是根据选项决定行为的好工具,用户的每个选择都可以对应 一个特定的case标签
- 使用while语句可以实现重复访问菜单的功能。
伪代码;
获取代码
当选项不是‘q’时
转至相应的选项并执行
获取下一个选项
8.7.2 使执行更顺利
缓冲输入依旧带来些麻烦,程序把用户每次按下 Return 键产生的换行符视为错误响应。为了让程序的界面更流畅,该函数应该跳过这些换行符。
一种是用名为get_first()的新函数替换 getchar()函数,读取一行的第1个字符并丢弃剩余的字符。这种方法的优点 是,把类似act这样的输入视为简单的a
8.7.3 混合字符和数值输入
混合字符和数值输入会产生一些问题
示例
#include <stdio.h>
char get_choice(void);
char get_first(void);
int get_int(void);
void count(void);
int main(void)
{
int choice;
void count(void);
while ((choice = get_choice()) != 'q')
{
switch (choice)
{
case 'a': printf("Buy low, sell high.\n");
break;
case 'b': putchar('\a'); /* ANSI */
break;
case 'c': count();
break;
default: printf("Program error!\n");
break;
}
}
printf("Bye.\n");
return 0;
}
void count(void)
{
int n, i;
printf("Count how far? Enter an integer:\n");
n = get_int();
for (i = 1; i <= n; i++)
printf("%d\n", i);
while (getchar() != '\n')
continue;
}
char get_choice(void)
{
int ch;
printf("Enter the letter of your choice:\n");
printf("a. advice b. bell\n");
printf("c. count q. quit\n");
ch = get_first();
while ((ch < 'a' || ch > 'c') && ch != 'q')
{
printf("Please respond with a, b, c, or q.\n");
ch = get_first();
}
return ch;
}
char get_first(void)
{
int ch;
ch = getchar();
while (getchar() != '\n')
continue;
return ch;
}
int get_int(void)
{
int input;
char ch;
while (scanf("%d", &input) != 1)
{
while ((ch = getchar()) != '\n')
putchar(ch); // 处理错误输出
printf(" is not an integer.\nPlease enter an ");
printf("integer value, such as 25, -178, or 3: ");
}
return input;
}
作业
编写一个程序,显示一个提供加法、减法、乘法、除法的菜单。获得 用户选择的选项后,程序提示用户输入两个数字,然后执行用户刚才选择的 操作。该程序只接受菜单提供的选项。程序使用float类型的变量储存用户输 入的数字,如果用户输入失败,则允许再次输入。进行除法运算时,如果用 户输入0作为第2个数(除数),程序应提示用户重新输入一个新值。
#include<stdio.h>
int main()
{
char chen;
float m,n,jie;
printf("请输入您的选择:\n"
"a.加法 b.减法\n"
"c.乘法 d.除法\n"
"q.退出\n");
while ((chen=getchar())!='q')
{
fflush(stdin);
if (chen!='a' && chen!='b' && chen!='c' && chen!='d' && chen!='\r')
{
printf("请重新输入!\n");
}
switch(chen)
{
case 'a':
printf("请输入两个数字:\n");
scanf("%f %f",&n,&m);
fflush(stdin);
jie=n+m;
printf("m+n=%.2f",jie);
break;
case 'b':
printf("请输入两个数字:\n");
scanf("%f %f",&n,&m);
fflush(stdin);
jie=n-m;
printf("n-m=%.2f",jie);
break;
case 'c':
printf("请输入两个数字:\n");
scanf("%f %f",&n,&m);
fflush(stdin);
jie=n*m;
printf("n*m=%.2f",jie);
break;
case 'd':
printf("请输入两个数字:\n");
scanf("%f %f",&n,&m);
if (m==0)
{
printf("请重新输入m的值:\n");
scanf("%f",&m);
}
fflush(stdin);
jie=n/m;
printf("n/m=%.2f",jie);
break;
}
}
return 0;
}
作业过程中输出得到了inf这样的值,查找到的原因如下:
nf一般是因为得到的数值,超出浮点数的表示范围(溢出,即阶码部分超过其能表示的最大值);而nan一般是因为对浮点数进行了未定义的操作,如对-1开方。
2、nan==nan
结果是0或false,即不能和nan进行比较,和nan进行比较得到的结果总是false或0。所以可以用函数: int
isNumber(double d){return (d==d);}来判断d是否为nan,若d是nan则返回0,否则返回非零值。
3、1.0/0.0等于inf,-1.0/0.0等于-inf,0.0+inf=inf;
4、对负数开方sqrt(-1.0)、对负数求对数(log(-1.0))、0.0/0.0、0.0*inf、inf/inf、inf-inf这些操作都会得到nan。(0/0会产生操作异常;0.0/0.0不会产生操作异常,而是会得到nan)
5、得到inf时就查看是否有溢出或者除以0,得到nan时就查看是否有非法操作。
6、C语言的头文件<float.h>中,有定义的常量DBL_MAX,这个常量表示“能表示出来的最大的双精度浮点型数值”。<float.h>中还有常量DBL_MIN,DBL_MIN表示可以用规格化表示的最小的正浮点数,但DBL_MIN并不是最小的正浮点数,因为可以用可以用非规格化浮点数表示的更小。可以用函数:int
isFiniteNumber(double d){return
(d<=DBL_MAX&&d>=-DBL_MAX);}来判断d是否为一个finite数(既不是inf,又不是nan(加入d为nan,则d参加比较就会得到false(0)值))。
7、1.0/inf等于0.0。
8、inf是可以与其他浮点数进行比较的,即可以参与<=、>+、==、!=等运算。
下面这几个宏(用宏实现的,使用时跟函数的形式基本相同)是判断一个表达式的结果是否为inf、nan或其他:
头文件:include<math.h>
宏的用法(类似于函数原型):int fpclassify(x);
int
isfinite(x);
int
isnormal(x);
int isnan(x);
int isinf(x);
具体用法:
1、int
fpclassify(x)
用来查看浮点数x的情况,fpclassify可以用任何浮点数表达式作为参数,fpclassify的返回值有以下几种情况。
FP_NAN:x是一个“not a number”。
FP_INFINITE: x是正、负无穷。
FP_ZERO: x是0。
FP_SUBNORMAL: x太小,以至于不能用浮点数的规格化形式表示。
FP_NORMAL: x是一个正常的浮点数(不是以上结果中的任何一种)。
2、int
isfinite(x)
当(fpclassify(x)!=FP_NAN&&fpclassify(x)!=FP_INFINITE)时,此宏得到一个非零值。
3、int
isnormal(x) 当(fpclassify(x)==FP_NORMAL)时,此宏得到一个非零值。
4、int
isnan(x) 当(fpclassify(x)==FP_NAN)时,此宏返回一个非零值。
5、int
isinf(x) 当x是正无穷是返回1,当x是负无穷时返回-1。(有些较早的编译器版本中,无论是正无穷还是负无穷,都返回非零值,不区分正负无穷)。
*** INF表示“无穷大”,是infinite的缩写。***
***NAN表示“无效数字”,是Not a number的缩写。 ***
9.1 复习函数
函数(function)是完成特定任务的独立程序代码 单元。
使用函数可以省去编写重复代码的苦差。如 果程序要多次完成某项任务,那么只需编写一个合适的函数,就可以在需要 时使用这个函数,或者在不同的程序中使用该函数,就像许多程序中使用 putchar()一样。其次,即使程序只完成某项任务一次,也值得使用函数。因 为函数让程序更加模块化,从而提高了程序代码的可读性,更方便后期修 改、完善。
9.1.1 创建并使用简单的函数
示例
#include <stdio.h>
#define NAME "GIGATHINK, INC."
#define ADDRESS "101 Megabuck Plaza"
#define PLACE "Megapolis, CA 94904"
#define WIDTH 40
void starbar(void); /* 函数原型 */
int main(void)
{
starbar();
printf("%s\n", NAME);
printf("%s\n", ADDRESS);
printf("%s\n", PLACE);
starbar(); /* 使用函数 */
return 0;
}
void starbar(void) /* 定义函数 */
{
int count;
for (count = 1; count <= WIDTH; count++)
putchar('*');
putchar('\n');
}
9.1.2 分析程序
函数原型(function prototype)告诉编 译器函数starbar()的类型;函数调用(function call)表明在此处执行函数; 函数定义(function definition)明确地指定了函数要做什么。
函数和变量一样,有多种类型。任何程序在使用函数之前都要声明该函 数的类型。
例如: void starbar(void);
圆括号表明starbar是一个函数名。第1个void是函数类型,void类型表明 函数没有返回值。第2个void(在圆括号中)表明该函数不带参数。分号表 明这是在声明函数,不是定义函数。也就是说,这行声明了程序将使用一个 名为starbar()、没有返回值、没有参数的函数,并告诉编译器在别处查找该 函数的定义。
一般而言,函数原型指明了函数的返回值类型和函数接受的参数类型。 这些信息称为该函数的签名(signature)。对于starbar()函数而言,其签名是 该函数没有返回值,没有参数。
程序中strarbar()和main()的定义形式相同。首先函数头包括函数类型、 函数名和圆括号,接着是左花括号、变量声明、函数表达式语句,最后以右 花括号结束(见图9.2)。注意,函数头中的starbar()后面没有分号,告诉编 译器这是定义starbar(),而不是调用函数或声明函数原型。
程序把 starbar()和 main()放在一个文件中。当然,也可以把它们分别放 在两个文件中。把函数都放在一个文件中的单文件形式比较容易编译,而使 用多个文件方便在不同的程序中使用同一个函数。如果把函数放在一个单独 的文件中,要把#define 和#include 指令也放入该文件。现在,先把所有的函数都放在一个文件中。main()的右花 括号告诉编译器该函数结束的位置,后面的starbar()函数头告诉编译器 starbar()是一个函数。
starbar()函数中的变量count是局部变量(local variable),意思是该变 量只属于starbar()函数。***可以在程序中的其他地方(包括main()中)使用 count,这不会引起名称冲突,它们是同名的不同变量。 ***
如果把starbar()看作是一个黑盒,那么它的行为是打印一行星号。不用 给该函数提供任何输入,因为调用它不需要其他信息。而且,它没有返回 值,所以也不给 main()提供(或返回)任何信息。简而言之,starbar()不需 要与主调函数通信。
9.1.3 函数参数 需要通信的函数
示例
#include <stdio.h>
#include <string.h> /* 为strlen()提供原型 */
#define NAME "GIGATHINK, INC."
#define ADDRESS "101 Megabuck Plaza"
#define PLACE "Megapolis, CA 94904"
#define WIDTH 40
#define SPACE ' '
void show_n_char(char ch, int num);
int main(void)
{
int spaces;
show_n_char('*', WIDTH); /* 用符号常量作为参数 */
putchar('\n');
show_n_char(SPACE, 12); /* 用符号常量作为参数 */
printf("%s\n", NAME);
spaces = (WIDTH - strlen(ADDRESS)) / 2; /* 计算要跳过多少个空格*/
show_n_char(SPACE, spaces); /* 用一个变量作为参数*/
printf("%s\n", ADDRESS);
show_n_char(SPACE, (WIDTH - strlen(PLACE)) / 2);
printf("%s\n", PLACE); /* 用一个表达式作为参数*/
show_n_char('*', WIDTH);
putchar('\n');
return 0;
}
/* show_n_char()函数的定义 */
void show_n_char(char ch, int num)
{
int count;
for (count = 1; count <= num; count++)
putchar(ch);
}
9.1.4 定义带形式参数的函数
该行告知编译器show_n_char()使用两个参数ch和num,ch是char类型, num是int类型。这两个变量被称为形式参数(formal argument,但是最近的标 准推荐使用formal parameter),简称形参。和定义在函数中变量一样,形式参数也是局部变量,属该函数私有。这意味着在其他函数中使用同名变量不 会引起名称冲突。每次调用函数,就会给这些变量赋值。
注意,ANSI C要求在每个变量前都声明其类型。也就是说,不能像普 通变量声明那样使用同一类型的变量列表:
***void dibs(int x, y, z) *** 无效的函数头
***void dubs(int x, int y, int z) ***这是对的
这里,圆括号中只有参数名列表,而参数的类型在后面声明。注意,普 通的局部变量在左花括号之后声明,而上面的变量在函数左花括号之前声 明。如果变量是同一类型,这种形式可以用逗号分隔变量名列表,如下所 示:
void dibs(x, y, z) int x, y, z;
9.1.5 声明带形式参数函数的原型
在使用函数之前,要用ANSI C形式声明函数原型:
void show_n_char(char ch, int num);
当函数接受参数时,函数原型用逗号分隔的列表指明参数的数量和类 型。根据个人喜好,你也可以省略变量名:
void show_n_char(char, int);
在原型中使用变量名并没有实际创建变量,char仅代表了一个char类型 的变量,以此类推。再次提醒读者注意,ANSI C也接受过去的声明函数形 式,即圆括号内没有参数列表:
9.1.6 调用带实际参数的函数
实际参数是出现在函数调用圆括号中的表达式。形式参数是函数定义的 函数头中声明的变量。调用函数时,创建了声明为形式参数的变量并初始化 为实际参数的求值结果。
9.1.7 黑盒的视角
黑盒方法的核心部分是:ch、num和count都是show_n_char()私有的局部 变量。如果在main()中使用同名变量,那么它们相互独立,互不影响。也就 是说,如果main()有一个count变量,那么改变它的值不会改变show_n_char() 中的count,反之亦然。黑盒里发生了什么对主调函数是不可见的。
9.1.8 使用return从函数中返回值
测试函数的程序有时被称为驱动程序(driver), 该驱动程序调用一个函数。
设计函数的返回值可以把信息从被调函数传回主调函数。
示例
#include <stdio.h>
int imin(int, int);
int main(void)
{
int evil1, evil2;
printf("Enter a pair of integers (q to quit):\n");
while (scanf("%d %d", &evil1, &evil2) == 2)//这里scanf的返回值就是2
{
printf("The lesser of %d and %d is %d.\n",
evil1, evil2, imin(evil1, evil2));
printf("Enter a pair of integers (q to quit):\n");
}
printf("Bye.\n");
return 0;
}
int imin(int n, int m)
{
int min;
if (n < m)
min = n;
else
min = m;
return min;
}
关键字return后面的表达式的值就是函数的返回值。在该例中,该函数 返回的值就是变量min的值。因为min是int类型的变量,所以imin()函数的类 型也是int。
变量min属于imin()函数私有,但是return语句把min的值传回了主调函 数。下面这条语句的作用是把min的值赋给lesser:
***lesser = imin(n,m); ***
但是不可以这样写:
imin(n,m);
lesser = min;
因为主调函数甚至不知道min的存在。记住,imin()中的变量是 imin()的局部变量。函数调用imin(evil1, evil2)只是把两个变量的值拷贝了一 份。 返回值不仅可以赋给变量,也可以被用作表达式的一部分。
answer = 2 * imin(z, zstar) + 25;
printf(“%d\n”, imin(-32 + answer, LIMIT));
返回值不一定是变量的值,也可以是任意表达式的值。
如果直接使用return;
则会终止函数,并把控制返回给主函数
因为 return 后面 没有任何表达式,所以没有返回值,只有在void函数中才会用到这种形式。
9.1.9 函数类型
声明函数时必须声明函数的类型。带返回值的函数类型应该与其返回值 类型相同,而没有返回值的函数应声明为void类型。如果没有声明函数的类 型,旧版本的C编译器会假定函数的类型是int。
(但是现在C99已经不允许了)
类型声明是函数定义的一部分。要记住,函数类型指的是返回值的类 型,不是函数参数的类型。例如,下面的函数头定义了一个带两个int类型参 数的函数,但是其返回值是double类型。
double klink(int a, int b)
作业
#include <stdio.h>
double min(double m,double n);
int main()
{
double m,n;
scanf("%lf %lf",&m,&n);
printf("这两个数的调和平均数是%lf",min(m,n));
return 0;
}
double min(double m,double n)
{
double q;
m=1/m;
n=1/n;
q=(m+n)/2;
q=1/q;
return q;
}
#include <stdio.h>
double min(double m,double n);
int main()
{
double m,n;
scanf("%lf %lf",&m,&n);
printf("这两个数小的是%lf",min(m,n));
return 0;
}
double min(double m,double n)
{
double q;
if (m>n)
q=n;
else
q=m;
return q;
}
9.2 ANSI C函数原型
下面是ANSI之前的函数声明,告知编译器imin()返回int类型的值:
int imin();
然而,以上函数声明并未给出imin()函数的参数个数和类型。因此,如 果调用imin()时使用的参数个数不对或类型不匹配,编译器根本不会察觉出 来。
9.2.1 问题所在
示例
#include <stdio.h>
int imax(); /* 旧式函数声明 */
int main(void)
{
printf("The maximum of %d and %d is %d.\n",3, 5, imax(3));
printf("The maximum of %d and %d is %d.\n",3, 5,
585
imax(3.0, 5.0));
return 0;
}
int imax(n, m)
int n, m;
{
return (n > m ? n : m);
}
第1次调用printf()时省略了imax()的一个参数,第2次调用printf()时用两 个浮点参数而不是整数参数。尽管有些问题,但程序可以编译和运行。
由于不同系统的内部机制不同,所以出现问题的 具体情况也不同。下面介绍的是使用P C和VA X的情况。主调函数把它的参 数储存在被称为栈(stack)的临时存储区,被调函数从栈中读取这些参数。 对于该例,这两个过程并未相互协调。主调函数根据函数调用中的实际参数 决定传递的类型,而被调函数根据它的形式参数读取值。因此,函数调用 imax(3)把一个整数放在栈中。当imax()函数开始执行时,它从栈中读取两个整数。而实际上栈中只存放了一个待读取的整数,所以读取的第 2 个值是当 时恰好在栈中的其他值。
第2次使用imax()函数时,它传递的是float类型的值。这次把两个double 类型的值放在栈中(回忆一下,当float类型被作为参数传递时会被升级为 double类型)。在我们的系统中,两个double类型的值就是两个64位的值, 所以128位的数据被放在栈中。当imax()从栈中读取两个int类型的值时,它 从栈中读取前64位。在我们的系统中,每个int类型的变量占用32位。这些数 据对应两个整数,其中较大的是3886。 ****
9.2.2 ANSI的解决方案
ANSI C标准要求在函数声明时还要声明变量 的类型,即使用函数原型(function prototype)来声明函数的返回类型、参 数的数量和每个参数的类型。未标明 imax()函数有两个 int 类型的参数,可 以使用下面两种函数原型来声明
int imax(int, int);
int imax(int a, int b);
第1种形式使用以逗号分隔的类型列表,第2种形式在类型后面添加了变 量名。***这里的变量名是假名,不必与函数定义的形式参数名一致。 ***
9.2.3 无参数和未指定参数
void print_name();
一个支持ANSI C的编译器会假定用户没有用函数原型来声明函数,它 将不会检查参数。
为了表明函数确实没有参数,应该在圆括号中使用void关 键字:
void print_name(void);
支持ANSI C的编译器解释为print_name()不接受任何参数。
然后在调用 该函数时,编译器会检查以确保没有使用参数。
一些函数接受(如,printf()和scanf())许多参数。例如对于printf(),第1个参数是字符串,但是其余参数的类型和数量都不固定。
对于这种情况, ANSI C允许使用部分原型。例如,对于printf()可以使用下面的原型:
int printf(const char *, …);
这种原型表明,第1个参数是一个字符串;可 能还有其他未指定的参数。
***C库通过stdarg.h头文件提供了一个定义这类(形参数量不固定的)函数 的标准方法。 ***
9.2.4 函数原型的优点
函数原型是C语言的一个强有力的工具,它让编译器捕获在使用函数时 可能出现的许多错误或疏漏。
9.3递归
C允许函数调用它自己,这种调用过程称为递归(recursion)。递归有 时难以捉摸,有时却很方便实用。结束递归是使用递归的难点,因为如果递 归代码中没有终止递归的条件测试部分,一个调用自己的函数会无限递归。
可以使用循环的地方通常都可以使用递归。有时用循环解决问题比较 好,但有时用递归更好。递归方案更简洁,但效率却没有循环高。
9.3.1示例
#include <stdio.h>
void up_and_down(int);
int main(void)
{
up_and_down(1);
return 0;
}
void up_and_down(int n)
{
printf("Level %d: n location %p\n", n, &n); // #1
if (n < 4)
up_and_down(n + 1);
printf("LEVEL %d: n location %p\n", n, &n); // #2
}
输出结果:
Level 1: n location 0x0012ff48
Level 2: n location 0x0012ff3c
Level 3: n location 0x0012ff30
Level 4: n location 0x0012ff24
LEVEL 4: n location 0x0012ff24
LEVEL 3: n location 0x0012ff30
LEVEL 2: n location 0x0012ff3c
LEVEL 1: n location 0x0012ff48
每级递归的变量 n 都属于本级递归私有。
首先,main()调用了带参 数1的up_and_down()函数,执行结果是up_and_down()中的形式参数n的值是 1,所以打印语句#1打印Level 1。然后,由于n小于4,up_and_down()(第1级)调用实际参数为n + 1(或2)的up_and_down()(第2级)。于是第2级调 用中的n的值是2,打印语句#1打印Level 2。与此类似,下面两次调用打印的 分别是Level 3和Level 4。 当执行到第4级时,n的值是4,所以if测试条件为假。up_and_down()函 数不再调用自己。第4级调用接着执行打印语句#2,即打印LEVEL 4,因为n 的值是4。此时,第4级调用结束,控制被传回它的主调函数(即第3级调 用)。在第3级调用中,执行的最后一条语句是调用if语句中的第4级调用。 被调函数(第4级调用)把控制返回在这个位置,因此,第3级调用继续执行 后面的代码,打印语句#2打印LEVEL 3。然后第3级调用结束,控制被传回 第2级调用,接着打印LEVEL2,以此类推。
好比有一条函数调用链——fun1()调用 fun2()、fun2()调用 fun3()、fun3()调用fun4()。当 fun4()结束时,控制传回 fun3();当fun3()结束时,控制传回 fun2();当fun2()结束时,控制传回 fun1()。递归的情况与此类似,只不过fun1()、fun2()、fun3()和fun4()都是相同 的函数。
9.3.2 递归的原理
第1,每级函数调用都有自己的变量。也就是说,第1级的n和第2级的n 不同,所以程序创建了4个单独的变量,每个变量名都是n,但是它们的值各 不相同。当程序最终返回 up_and_down()的第1 级调用时,最初的n仍然是它 的初值1 。
第2,每次函数调用都会返回一次。当函数执行完毕后,控制权将被传 回上一级递归。程序必须按顺序逐级返回递归,从某级up_and_down()返回 上一级的up_and_down(),不能跳级回到main()中的第1级调用。
第3,递归函数中位于递归调用之前的语句,均按被调函数的顺序执 行。例如,程序清单9.6中的打印语句#1位于递归调用之前,它按照递归的 顺序:第1级、第2级、第3级和第4级,被执行了4次。
第4,递归函数中位于递归调用之后的语句,均按被调函数相反的顺序 执行。例如,打印语句#2位于递归调用之后,其执行的顺序是第4级、第3 级、第2级、第1级。递归调用的这种特性在解决涉及相反顺序的编程问题时 很有用。
第5,虽然每级递归都有自己的变量,但是并没有拷贝函数的代码。程 序按顺序执行函数中的代码,而递归调用就相当于又从头开始执行函数的代 码。除了为每次递归调用创建变量外,递归调用非常类似于一个循环语句。 实际上,递归有时可用循环来代替,循环有时也能用递归来代替。
最后,递归函数必须包含能让递归调用停止的语句。通常,递归函数都 使用if或其他等价的测试条件在函数形参等于某特定值时终止递归。为此, 每次递归调用的形参都要使用不同的值。
9.3.3 尾递归
最简单的递归形式是把递归调用置于函数的末尾,即正好在 return 语句 之前。这种形式的递归被称为尾递归(tail recursion),因为递归调用在函 数的末尾。尾递归是最简单的递归形式,因为它相当于循环。
用递归和循环来计算都没问题,那么到底应该使用哪一个?一般而 言,选择循环比较好。首先,每次递归都会创建一组变量,所以递归使用的 内存更多,而且每次递归调用都会把创建的一组新变量放在栈中。递归调用 的数量受限于内存空间。其次,由于每次函数调用要花费一定的时间,所以 递归的执行速度较慢。那么,演示这个程序示例的目的是什么?因为尾递归 是递归中最简单的形式,比较容易理解。在某些情况下,不能用简单的循环 代替递归,因此读者还是要好好理解递归。
9.3.4 递归和倒序计算
递归在处理倒序时非常方便(在解决这类问题中,递归比循环简单)。
以二进制打印整数
#include <stdio.h>
void to_binary(unsigned long n);
int main(void)
{
unsigned long number;
printf("Enter an integer (q to quit):\n");
while (scanf("%lu", &number) == 1)
{
printf("Binary equivalent: ");
to_binary(number);
putchar('\n');
printf("Enter an integer (q to quit):\n");
}
printf("Done.\n");
return 0;
}
void to_binary(unsigned long n) /* 递归函数 */
{
int r;
r = n % 2;
if (n >= 2)
to_binary(n / 2);
putchar(r == 0 ? '0' : '1');
return;
}
9.3.5 递归的优缺点
递归既有优点也有缺点。优点是递归为某些编程问题提供了最简单的解 决方案。缺点是一些递归算法会快速消耗计算机的内存资源。另外,递归不 方便阅读和维护。
假设调用 Fibonacci(40)。这是第1 级递归调用,将 创建一个变量 n。然后在该函数中要调用Fibonacci()两次,在第2级递归中要 分别创建两个变量n。这两次调用中的每次调用又会进行两次调用,因而在 第3级递归中要创建4个名为n的变量。此时总共创建了7个变量。由于每级递 归创建的变量都是上一级递归的两倍,所以变量的数量呈指数增长!在第 5 章中介绍过一个计算小麦粒数的例子,按指数增长很快就会产生非常大的 值。在本例中,指数增长的变量数量很快就消耗掉计算机的大量内存,很可 能导致程序崩溃。 虽然这是个极端的例子,但是该例说明:在程序中使用递归要特别注 意,尤其是效率优先的程序。
main()函数是否与其他函数不同?是的,main()的确有点特殊。当 main()与程序中的其他函数放在一起时,最开始执行的是main()函数中的第1 条语句,但是这也是局限之处。main()也可以被自己或其他函数递归调用 ——尽管很少这样做。
作业
#include <stdio.h>
double power(double n, int p); // ANSI函数原型
double powers(double n, int p);
int main(void)
{
double x, xpow,xpows;
int exp;
printf("请输入:\n");
while (scanf("%lf%d", &x, &exp) == 2)
{
xpow = power(x, exp); // 函数调用
printf("循环输出的:%.3g to the power %d is %.5g\n", x, exp, xpow);
xpows=powers(x,exp);
printf("递归输出的:%.3g to the power %d is %.5g\n", x, exp, xpows);
printf("Enter next pair of numbers or q to quit.\n");
}
printf("Hope you enjoyed this power trip -- bye!\n");
return 0;
}
double power(double n, int p) // 函数定义
{
double pow = 1;
int i;
if (p>0)
{
for (i = 1; i <= p; i++)
pow *= n;
}
if (p<0)
{
for (i = 1; i <= -p; i++)
pow *= 1/n;
}
if (p==0)
{
pow=1;
}
if (n==0)
{
pow=0;
}
if (n==0 && p==0)
{
printf("0的0次幂未定义,已为您处理为1\n");
pow=1;
}
return pow; // 返回pow的值
}
double powers(double n, int p)
{
if (p > 0)
return n * powers(n, p - 1);
if (p == 0)
return 1;
}
9.4 编译多源代码文件的程序
使用多个函数最简单的方法是把它们都放在同一个文件中,然后像编译 只有一个函数的文件那样编译该文件即可。其他方法因操作系统而异。
9.4.1 UNIX
假定在UNIX系统中安装了UNIX C编译器cc(最初的cc已经停用,但是 许多UNIX系统都给cc命令起了一个别名用作其他编译器命令,典型的是gcc 或clang)。
假设file1.c和file2.c是两个内含C函数的文件,下面的命令将编译 两个文件并生成一个名为a.out的可执行文件:
cc file1.c file2.c
另外,还生成两个名为file1.o和file2.o的目标文件。如果后来改动了 file1.c,而file2.c不变,可以使用以下命令编译第1个文件,并与第2个文件 的目标代码合并:
cc file1.c file2.o
9.4.2 Linux
假定Linux系统安装了GNU C编译器GCC。假设file1.c和file2.c是两个内 含C函数的文件,下面的命令将编译两个文件并生成名为a.out的可执行文 件:
gcc file1.c file2.c
另外,还生成两个名为file1.o和file2.o的目标文件。如果后来改动了 file1.c,而file2.c不变,可以使用以下命令编译第1个文件,并与第2个文件 的目标代码合并:
gcc file1.c file2.o
9.4.3 DOS命令行编译器
绝大多数DOS命令行编译器的工作原理和UNIX的cc命令类似,只不过 使用不同的名称而已。其中一个区别是,对象文件的扩展名是.obj,而不 是.o。一些编译器生成的不是目标代码文件,而是汇编语言或其他特殊代码 的中间文件。
9.4.4 windows和苹果的IDE编译器
Windows和Macintosh系统使用的集成开发环境中的编译器是面向项目 的。项目(project)描述的是特定程序使用的资源。资源包括源代码文件。 这种IDE中的编译器要创建项目来运行单文件程序。对于多文件程序,要使 用相应的菜单命令,把源代码文件加入一个项目中。要确保所有的源代码文 件都在项目列表中列出。许多IDE都不用在项目列表中列出头文件(即扩展 名为.h的文件),因为项目只管理使用的源代码文件,源代码文件中的 #include指令管理该文件中使用的头文件。但是,Xcode要在项目中添加头文 件。
9.4.5 使用头文件
如果把main()放在第1个文件中,把函数定义放在第2个文件中,那么第 1个文件仍然要使用函数原型。把函数原型放在头文件中,就不用在每次使 用函数文件时都写出函数的原型。C 标准库就是这样做的,例如,把I/O函 数原型放在stdio.h中,把数学函数原型放在math.h中。你也可以这样用自定 义的函数文件。
另外,程序中经常用C预处理器定义符号常量。这种定义只储存了那些 包含#define指令的文件。如果把程序的一个函数放进一个独立的文件中,你 也可以使用#define指令访问每个文件。最直接的方法是在每个文件中再次输 入指令,但是这个方法既耗时又容易出错。另外,还会有维护的问题:如果 修改了#define 定义的值,就必须在每个文件中修改。更好的做法是,把 #define 指令放进头文件,然后在每个源文件中使用#include指令包含该文件 即可。
把函数原型和已定义的字符常量放在头文件中是一个良好的编程习惯。
9.5 查找地址:&运算符
指针(pointer)是 C 语言最重要的(有时也是最复杂的)概念之一,用 于储存变量的地址。前面使用的scanf()函数中就使用地址作为参数。如果主调函数不使用return返回的值,则必须通过地址才能修改主调函 数中的值。
一元&运算符给出变量的存储地址。如果pooh是变量名,那么&pooh是 变量的地址。可以把地址看作是变量在内存中的位置。
在 FORTRAN中,子例程会影响主调例程的原始变量。子例程的变量名可能与 原始变量不同,但是它们的地址相同。但是,在 C语言中不是这样。每个C 函数都有自己的变量。这样做更可取,因为这样做可以防止原始变量被被调 函数中的副作用意外修改。
9.6 更改主调函数中的变量
有时需要在一个函数中更改其他函数的变量。
但是传统的方法并不可取,示例
#include <stdio.h>
void interchange(int u, int v); /* 声明函数 */
int main(void)
{
int x = 5, y = 10;
printf("Originally x = %d and y = %d.\n", x, y);
interchange(x, y);
printf("Now x = %d and y = %d.\n", x, y);
return 0;
}
void interchange(int u, int v) /* 定义函数 */
{
int temp;
temp = u;
u = v;
v = temp;
}
输出如下:
Originally x = 5 and y = 10.
Now x = 5 and y = 10.
两个值并没有交换
问题出在把结果 传回 main()时。interchange()使用的变量并不是main()中的变量。因此,交换 u和v的值对x和y的值没有影响!
但是如果加上return,虽然但是return也只能返回一个变量的值,这里交换的涉及了两个变量,这里就要使用指针了
程序清单
主函数
#include <stdio.h>
#include "hotel.h" /* 定义符号常量,声明函数 */
int main(void)
{
int nights;
double hotel_rate;
int code;
while ((code = menu()) != QUIT)
{
switch (code)
{
case 1: hotel_rate = HOTEL1;
break;
case 2: hotel_rate = HOTEL2;
break;
case 3: hotel_rate = HOTEL3;
break;
case 4: hotel_rate = HOTEL4;
break;
default: hotel_rate = 0.0;
printf("Oops!\n");
break;
}
nights = getnights();
showprice(hotel_rate, nights);
}
printf("Thank you and goodbye.\n");
return 0;
}
函数支持模块
#include <stdio.h>
#include "hotel.h"
int menu(void)
{
int code, status;
printf("\n%s%s\n", STARS, STARS);
printf("Enter the number of the desired hotel:\n");
printf("1) Fairfield Arms 2) Hotel Olympic\n");
printf("3) Chertworthy Plaza 4) The Stockton\n");
printf("5) quit\n");
printf("%s%s\n", STARS, STARS);
while ((status = scanf("%d", &code)) != 1 ||
(code < 1 || code > 5))
{
if (status != 1)
scanf("%*s"); // 处理非整数输入
printf("Enter an integer from 1 to 5, please.\n");
}
return code;
}
int getnights(void)
{
int nights;
printf("How many nights are needed? ");
while (scanf("%d", &nights) != 1)
{
scanf("%*s"); // 处理非整数输入
printf("Please enter an integer, such as 2.\n");
}
return nights;
}
void showprice(double rate, int nights)
{
int n;
double total = 0.0;
double factor = 1.0;
for (n = 1; n <= nights; n++, factor *= DISCOUNT)
total += rate * factor;
printf("The total cost will be $%0.2f.\n", total);
}
头文件
#define QUIT 5
#define HOTEL1 180.00
#define HOTEL2 225.00
#define HOTEL3 255.00
#define HOTEL4 355.00
#define DISCOUNT 0.95
#define STARS "**********************************"
// 显示选择列表
int menu(void);
// 返回预订天数
int getnights(void);
// 根据费率、入住天数计算费用
// 并显示结果
void showprice(double rate, int nights);
第十章 数组和指针
10.1 数组
数组由数据类型相同的一系列元素组成。需要使用数组 时,通过声明数组告诉编译器数组中内含多少元素和这些元素的类型。编译 器根据这些信息正确地创建数组。普通变量可以使用的类型,数组元素都可 以用。
要访问数组中的元素,通过使用数组下标数(也称为索引)表示数组中 的各元素。数组元素的编号从0开始,所以candy[0]表示candy数组的第1个元 素,candy[364]表示第365个元素,也就是最后一个元素。
10.1.1 初始化数组
数组通常被用来储存程序需要的数据。
int powers[8] = {1,2,4,6,8,16,32,64}; /* 从ANSI C开始支持这种初始化 */
用以逗号分隔的值列表(用花括号括起来)来初始化数组, 各值之间用逗号分隔。在逗号和值之间可以使用空格。根据上面的初始化, 把 1 赋给数组的首元素(powers[0])
注意 使用const声明数组
有时需要把数组设置为只读。这样,程序只能从数组中检索值,不能把 新值写入数组。要创建只读数组,应该用const声明和初始化数组。
程序在运行过程中就不能修改该数组中的内容。和普通变 量一样,应该使用声明来初始化 const 数据,因为一旦声明为 const,便不能 再给它赋值。
当初始化列表中的值少于数组元素个数 时,编译器会把剩余的元素都初始化为0。也就是说,如果不初始化数组, 数组元素和未初始化的普通变量一样,其中储存的都是垃圾值;但是,如果 部分初始化数组,剩余的元素就会被初始化为0。
如果初始化列表的项数多于数组元素个数,编译器可没那么仁慈,它会 毫不留情地将其视为错误。
如果初始化数组时省略方括号中的数字,编译器会根据初始化列表中的 项数来确定数组的大小。
10.1.2 指定初始化器(C99)
C99 增加了一个新特性:指定初始化器(designated initializer)。利用 该特性可以初始化指定的数组元素。例如,只初始化数组中的最后一个元 素。对于传统的C初始化语法,必须初始化最后一个元素之前的所有元素, 才能初始化它:
int arr[6] = {0,0,0,0,0,212}; // 传统的语法
而C99规定,可以在初始化列表中使用带方括号的下标指明待初始化的 元素:
int arr[6] = {[5] = 212}; // 把arr[5]初始化为212
指定初始化器的两个重要特性。第一,如果指定初始化 器后面有更多的值,如该例中的初始化列表中的片段:[4] = 31,30,31,那么 后面这些值将被用于初始化指定元素后面的元素。也就是说,在days[4]被初 始化为31后,days[5]和days[6]将分别被初始化为30和31。第二,如果再次初 始化指定的元素,那么最后的初始化将会取代之前的初始化。例如,程序清 单10.5中,初始化列表开始时把days[1]初始化为28,但是days[1]又被后面的 指定初始化[1] = 29初始化为29。
10.1.3 给数组赋值
声明数组后,可以借助数组下标(或索引)给数组元素赋值。例如,下 面的程序段给数组的所有元素赋值:
用循环赋值,示例
#include <stdio.h>
#define SIZE 50
int main(void)
{
int counter, evens[SIZE];
for (counter = 0; counter < SIZE; counter++)
evens[counter] = 2 * counter;
...
}
不允许的操作呢
#define SIZE 5
int main(void)
{
int oxen[SIZE] = {5,3,2,8}; /* 初始化没问题 */
int yaks[SIZE];
yaks = oxen; /* 不允许 */
yaks[SIZE] = oxen[SIZE]; /* 数组下标越界 */
yaks[SIZE] = {5,3,2,8}; /* 不起作用 */
}
oxen数组的最后一个元素是oxen[SIZE-1],所以oxen[SIZE]和yaks[SIZE] 都超出了两个数组的末尾。
10.1.4 数组边界
在使用数组时,要防止数组下标超出边界。也就是说,必须确保下标是 有效的值。
int doofi[20];
那么在使用该数组时,要确保程序中使用的数组下标在0~19的范围 内,因为编译器不会检查出这种错误(但是,一些编译器发出警告,然后继 续编译程序)。
在C标准中,使用越界下标的 结果是未定义的。这意味着程序看上去可以运行,但是运行结果很奇怪,或 异常中止。
不检查边界,C 程序可以运行更快。编译器没必要捕获所有的下标错 误,因为在程序运行之前,数组的下标值可能尚未确定。因此,为安全起 见,编译器必须在运行时添加额外代码检查数组的每个下标值,这会降低程 序的运行速度。C 相信程序员能编写正确的代码,这样的程序运行速度更 快。
10.1.5 指定数组的大小
int m = 8; float a1[5]; // 可以 float a2[5*2 + 1]; //可以 float a3[sizeof(int) + 1]; //可以 float a4[-4]; // 不可以,数组大小必须大于0 float a5[0]; // 不可以,数组大小必须大于0 float a6[2.5]; // 不可以,数组大小必须是整数 float a7[(int)2.5]; // 可以,已被强制转换为整型常量 float a8[n]; // C99之前不允许 float a9[m]; // C99之前不允许
上面的注释表明,以前支持C90标准的编译器不允许后两种声明方式。 而C99标准允许这样声明,这创建了一种新型数组,称为变长数组 (variable-length array)或简称 VLA(C11 放弃了这一创新的举措,把VLA 设定为可选,而不是语言必备的特性)。
10.2 多维数组
float rain[5][12; // 内含5个数组元素的数组,每个数组元素内含12个 float类型的元素
float rain{5][12]; // rain是一个内含5个元素的数组
floatrain[5][12 ; // 一个内含12个float类型元素的数组
这说明每个元素的类型是float[12],也就是说,rain的每个元素本身都 是一个内含12个float类型值的数组。
根据以上分析可知,rain的首元素rain[0]是一个内含12个float类型值的 数组。所以,rain[1]、rain[2]等也是如此。如果 rain[0]是一个数组,那么它 的首元素就是 rain[0][0],第 2 个元素是rain[0][1],以此类推。简而言之, 数组rain有5个元素,每个元素都是内含12个float类型元素的数组,rain[0]是 内含12个float值的数组,rain[0][0]是一个float类型的值。假设要访问位于2 行3列的值,则使用rain[2][3](记住,数组元素的编号从0开始,所以2行指 的是第3行)。
10.2.1 初始化二维数组
初始化二维数组是建立在初始化一维数组的基础上。首先,初始化一维 数组如下:
sometype ar1[5] = {val1, val2, val3, val4, val5};
const float rain[YEARS][MONTHS] = { {4.3,4.3,4.3,3.0,2.0,1.2,0.2,0.2,0.4,2.4,3.5,6.6}, {8.5,8.2,1.2,1.6,2.4,0.0,5.2,0.9,0.3,0.9,1.4,7.3}, {9.1,8.5,6.7,4.3,2.1,0.8,0.2,0.2,1.1,2.3,6.1,8.4}, {7.2,9.9,8.4,3.3,1.2,0.8,0.4,0.0,0.6,1.7,4.3,6.2}, {7.6,5.6,3.8,2.8,3.8,0.2,0.0,0.0,0.0,1.3,2.6,5.2} };
这个初始化使用了5个数值列表,每个数值列表都用花括号括起来。第1 个列表的数据用于初始化数组的第1行,第2个列表的数据用于初始化数组的 第2行,以此类推。前面讨论的数据个数和数组大小不匹配的问题同样适用 于这里的每一行。也就是说,如果第1个列表中只有10个数,则只会初始化 数组第1行的前10个元素,而最后两个元素将被默认初始化为0。如果某列表 中的数值个数超出了数组每行的元素个数,则会出错,但是这并不会影响其 他行的初始化。
也可以使用两个循环初始化二维数组
10.2.2 其他多维数组
int box[10][20][30]; 三维数组
可以把一维数组想象成一行数据,把二维数组想象成数据表,把三维数 组想象成一叠数据表。例如,把上面声明的三维数组box想象成由10个二维 数组(每个二维数组都是20行30列)堆叠起来。
通常,处理三维数组要使用3重嵌套循环,处理四维数组要使用4重嵌套 循环。对于其他多维数组,以此类推。
作业
4.编写一个函数,返回储存在double类型数组中最大值的下标,并在一 个简单的程序中测试该函数。
5.编写一个函数,返回储存在double类型数组中最大值和最小值的差 值,并在一个简单的程序中测试该函数。
(两道题写在一个程序用一个代码)
#include <stdio.h>
int max(const double a[], int n);
int chazhi(const double a[], int n);
int main(void)
{
double t;
int a,q;
double b[5] = {1.0, 4.0, 3.0, 2.0, 5.0};
a = max(b, 5);
q= chazhi(b,5);
printf("最大值的下标是%d 最大值与最小值的差值是%d\n", a,q);
return 0;
}
int max(const double a[], int n)
{
int j,m;
double max = a[0];
double min = a[0];
for (j = 1; j < n; j++)
{
if (max < a[j])
{
max = a[j];
}
}
for (j = 1; j < n; j++)
{
if (min > a[j])
{
min = a[j];
}
}
m=max-min;
return m;
}
int chazhi(const double a[], int n)
{
int j,m;
double max = a[0];
double min = a[0];
for (j = 1; j < n; j++)
{
if (max < a[j])
{
max = a[j];
}
}
for (j = 1; j < n; j++)
{
if (min > a[j])
{
min = a[j];
}
}
m=max-min;
return m;
}
作业
7.编写一个程序,初始化一个double类型的二维数组,使用编程练习2中
的一个拷贝函数把该数组中的数据拷贝至另一个二维数组中(因为二维数组
是数组的数组,所以可以使用处理一维数组的拷贝函数来处理数组中的每个
子数组)。
#include<stdio.h>
#include<string.h>
int main()
{
int i,j;
char a[3][3]={{1,2,3},{4,5,6},{7,8,9}};
char b[3][3];
for(i=0; i<3; i++)
{
for(j=0; j<3; j++)
{
//printf("数组a是:\n");
printf("%d ", a[i][j]);
}
printf("\n");
}
strcpy(b,a);
//printf("数组b复制a是:\n");
for(i=0; i<3; i++)
{
for(j=0; j<3; j++)
{
printf("%d ", b[i][j]);
}
printf("\n");
}
return 0;
}
如果处理的是char类型可以用strcpy函数。
正文
#include<stdio.h>
#include<string.h>
double test(double a[3][3]);
int main()
{
int i,j;
double a[3][3]={{1,2,3},{4,5,6},{7,8,9}};
for(i=0; i<3; i++)
{
for(j=0; j<3; j++)
{
printf("%lf ", a[i][j]);
}
printf("\n");
}
test(a);
return 0;
}
double test(double a[3][3])//这里要是不给里面加数字报错 表达式必须是指向完整对象类型的指针
{
int i,j;
double b[3][3];
for(i=0; i<3; i++)
{
for(j=0; j<3; j++)
{
b[i][j]=a[i][j];
}
printf("\n");
}
for(i=0; i<3; i++)
{
for(j=0; j<3; j++)
{
printf("%lf ", b[i][j]);
}
printf("\n");
}
}
- 编写一个函数,把double类型数组中的数据倒序排列,并在一个简单 的程序中测试该函数。
#include<stdio.h>
double test(double a[]);
int main()
{
double a[10];
for (int i=0;i<10;i++)
{
scanf("%ld",&a[i]);
}
test(a);
return 0;
}
double test(double a[])
{
for (int i=9;i>=0;i--)
{
printf("%ld ",a[i]);
}
return 0;
}
9.7 指针简介
指针(pointer)是一个值为内存地址 的变量(或数据对象)。正如char类型变量的值是字符,int类型变量的值是 整数,指针变量的值是地址。
ptr = &pooh; // 把pooh的地址赋给ptr
ptr“指向”pooh。ptr和&pooh的区别是ptr是变量, 而&pooh是常量。或者,ptr是可修改的左值,而&pooh是右值。
9.7.1 间接运算符: *
假设已知ptr指向bah,如下所示:
prt=&bah;
然后使用间接运算符(indirection operator)找出储存在bah中的值,该 运算符有时也称为解引用运算符(dereferencing operator)。不要把间接运算 符和二元乘法运算符()混淆,虽然它们使用的符号相同,但语法功能不 同。
val = *ptr; // 找出ptr指向的值
语句ptr = &bah;和val = *ptr;放在一起相当于下面的语句:
val = bah;
9.7.2 声明指针
声明指针变量时必须指定指针所指向变量的 类型,因为不同的变量类型占用不同的存储空间,一些指针操作要求知道操 作对象的大小。另外,程序必须知道储存在指定地址上的数据类型。long和 float可能占用相同的存储空间,但是它们储存数字却大相径庭。
int * pi; // pi是指向int类型变量的指针
char * pc; // pc是指向char类型变量的指针
float * pf, * pg; // pf、pg都是指向float类型变量的指针
类型说明符表明了指针所指向对象的类型,星号()表明声明的变量 是一个指针。int * pi;声明的意思是pi是一个指针,pi是int类型
pc指向的值(*pc)是char类型。pc本身是什么类型?我们描述它的类型 是“指向char类型的指针”。pc 的值是一个地址,在大部分系统内部,该地址 由一个无符号整数表示。但是,不要把指针认为是整数类型。一些处理整数 的操作不能用来处理指针,反之亦然。例如,可以把两个整数相乘,但是不 能把两个指针相乘。所以,指针实际上是一个新类型,不是整数类型。因 此,如前所述,ANSI C专门为指针提供了%p格式的转换说明。
9.7.3使用指针在函数间通信
示例,利用指针在另一个函数进行数值交换,平常的函数之间的变量互不影响,但是利用指针传的是变量地址,因此可以交换
#include <stdio.h>
void interchange(int * u, int * v);
int main(void)
{
int x = 5, y = 10;
printf("Originally x = %d and y = %d.\n", x, y);
interchange(&x, &y); // 把地址发送给函数
printf("Now x = %d and y = %d.\n", x, y);
return 0;
}
void interchange(int * u, int * v)
{
int temp;
temp = *u; // temp获得 u 所指向对象的值
*u = *v;
*v = temp;
}
该函数传递的不是x和y的值,而是它们的地址。这意味着出现在 interchange()原型和定义中的形式参数u和v将把地址作为它们的值。因此, 应把它们声明为指针。由于x和y是整数,所以u和v是指向整数的指针
一般而言,可以把变量相关的两类信息传递给函数。如果这种形式的函 数调用,那么传递的是x的值:
function1(x);
如果下面形式的函数调用,那么传递的是x的地址:
function2(&x);
第1种形式要求函数定义中的形式参数必须是一个与x的类型相同的变 量: int function1(int num)
第2种形式要求函数定义中的形式参数必须是一个指向正确类型的指 针:
针: int function2(int * ptr)
如果要计算或处理值,那么使用第 1 种形式的函数调用;如果要在被调 函数中改变主调函数的变量,则使用第2种形式的函数调用。我们用过的 scanf()函数就是这样。当程序要把一个值读入变量时(如本例中的num), 调用的是scanf(“%d”, &num)。scanf()读取一个值,然后把该值储存到指定的 地址上。
普通变量把值作为基本量,把地址作为通过&运算符获得的 派生量,而指针变量把地址作为基本量,把值作为通过*运算符获得的派生 量。
10.3数组和指针
详细示例
#include<stdio.h>
void quezhi(int a[],int len,int *min,int *max);
void try();
int main()
{
int a[]={1,2,3,4,5,6,7,8,9,11,22,33,44,98,66,77,88,55};
int min,max;
int b=sizeof(a)/sizeof(a[0]);//这里面的sizeofa[]里面可以填范围之内的,因为这东西就是一个代表字节为长度的,同一个数组一个数占的位一样的
printf("mian sizeof(a)=%lu\n",sizeof(a));
printf("mian%p %p %p %p\n",a,a[0],a[1],a[2]);
quezhi(a,sizeof(a)/sizeof(a[0]),&min,&max);
printf("main%d\n",a[0]);
printf("%d %d %d\n",min,max,b);
int *m=&min;
printf("*m=%d m[0]=%d\n",*m,m[0]);//*p==p[0]
printf("*a=%d\n",*a);//为什么*a就等于1000了,不是a[0]==1000?因为数组a的值是数组首地址
try();
}
void quezhi(int a[],int len,int *min,int *max) //这个还是指针的基本用法,找出最大的值和最小的值
{
int t;
printf ("quezhi sizeof(a)=%lu\n",sizeof(a));
printf("quezhi%p %p %p %p\n",a,a[0],a[1],a[2]);
a[0]=1000;
printf("quezhi%d\n",a[0]);
*min=*max=a[0];
for (int num=1;num<len;num++)
{
if (a[num]<*min)
{
*min=a[num];
/* code */
}
if (a[num]>*max)
{
*max=a[num];//因为这里是循环所以会挑出最大的值
/* code */
}
}
}
void try()
{
int i=5,j=7;
const int *p=&i;
printf("%d %d\n",i,*p);
}
//由此看以看出数组和指针存在某种联系,函数参数表中数组实际上就是指针,(一定是函数参数表)
//就比如sizeof(a)==sizeof(int*) ,但是它可以用数组运算符去运算
//数组变量是特殊的指针
// 1.数组变量本身表达地址,所以之前做的不需要取址符,比如之前学的
// int a[10]; scanf(“%c”,a);这里的a其实代表的就是地址,一般的要用&,所以可不可以理解为我就是用数组定义了一串地址然后把字符放进之前定义好的地址里面
// 上面的列子也是int a[10];int *a;根本不需要& 但是数组包含的单元是需要取值符号,(a==&a[0])
// 2.[]运算符可以对数组用,也可以对指针用
// 比如p[0]==p 这里表示的是p指向的那个值作为一个数组也就是p[0]
//3.*运算符可以对指针用,也可以对数组用
//4.数组变量是const的指针,所以不能被赋值
// 比如(int b[]; b=a)这件事不可以,数组变量不可以互相赋值,但是(int *q=a;)这件事是可以的
// 总而言之就是 int b[]–>int *const b; const 修饰b,使得b的值变成只读变量
//那么指针与const 指针本身可以是const 它所指向的值也可以是一个const
//第一种:指针是const 也就是指向了一个变量的地址就不可以再指向别的变量地址 写做int *const p=&i;这种
//第二种:所指的是const 写做const int p=&i 或者int constp=&i(指针不许动); 这里就是不可以改变*p的值,但是i值可变并且p也可以指向别的,总之就是它指向谁之后获取的值不可以改变 下面试一试
//判断哪个被const了的标志是const在的前面还是后面 const在前面,就是它所指向的东西被const不可以改变;在后面就是指针不可以被修改,地址被const了
//const数组 const int a[]={1,2,3,4,5};数组变量已经是const的指针了,这里的const表明数组的每个单元都是const int,所以要通过初始化进行赋值
//保护数组值,因为数组传入函数时传递的时地址,可以被改变,所以在传入函数时可以加上const加以保护, int sum(const int a[],int lenth);
我们举一个变相使用指针的例子:数组名是数组首元素的地址。也就是 说,如果flizny是一个数组,下面的语句成立:
flizny == &flizny[0]; // 数组名是该数组首元素的地址
程序清单10.8
#include <stdio.h>
#define SIZE 4
int main(void)
{
short dates[SIZE];
short * pti;
short index;
double bills[SIZE];
double * ptf;
pti = dates; // 把数组地址赋给指针
ptf = bills;
printf("%23s %15s\n", "short", "double");
for (index = 0; index < SIZE; index++)
printf("pointers + %d: %10p %10p\n", index, pti + index,
ptf + index);
return 0;
}
输出示例
short double
pointers + 0: 0x7fff5fbff8dc 0x7fff5fbff8a0
pointers + 1: 0x7fff5fbff8de 0x7fff5fbff8a8
pointers + 2: 0x7fff5fbff8e0 0x7fff5fbff8b0
pointers + 3: 0x7fff5fbff8e2 0x7fff5fbff8b8
第2行打印的是两个数组开始的地址,下一行打印的是指针加1后的地 址,以此类推。注意,地址是十六进制的,因此dd比dc大1,a1比a0大1。
0x7fff5fbff8dc + 1是否是0x7fff5fbff8de? 0x7fff5fbff8a0 + 1是否是0x7fff5fbff8a8?
**在C中,指针加1指的是增加一个存储单元。对数组而言,这意味 着把加1后的地址是下一个元素的地址,而不是下一个字节的地址(见图 10.3)。这是为什么必须声明指针所指向对象类型的原因之一。只知道地址 不够,因为计算机要知道储存对象需要多少字节(即使指针指向的是标量变 量,也要知道变量的类型,否则pt 就无法正确地取回地址上的值)。 ***
这里的赋值是把dates首元素的地址赋给指针变量pti
***指针加1,指针的值递增它所指向类型的大小(以字节为单位)。 ***
dates + 2 == &date[2] // 相同的地址
*(dates + 2) == dates[2] // 相同的值
了数组和指针的关系十分密切,可以使用指针标识数组的 元素和获得元素的值。从本质上看,同一个对象有两种表示法。实际上,C 语言标准在描述数组表示法时确实借助了指针。也就是说,定义ar[n]的意思 是*(ar + n)。可以认为*(ar + n)的意思是“到内存的ar位置,然后移动n个单 元,检索储存在那里的值”。
不要混淆 (dates+2)和dates+2。间接运算符()的优先级 高于+,所以dates+2相当于(*dates)+2:
*(dates + 2) // dates第3个元素的值
*dates + 2 // dates第1个元素的值加2
程序清单10.9
#include <stdio.h>
#define MONTHS 12
int main(void)
{
int days[MONTHS] = { 31, 28, 31, 30, 31, 30, 31, 31,
30, 31, 30, 31 };
int index;
for (index = 0; index < MONTHS; index++)
printf("Month %2d has %d days.\n", index + 1,
*(days + index)); //与 days[index]相同
return 0;
}
这里,days是数组首元素的地址,days + index是元素days[index]的地 址,而*(days + index)则是该元素的值,相当于days[index]。for循环依次引用 数组中的每个元素,并打印各元素的内容。
10.4 函数、数组和指针
示例
注意 声明数组形参
因为数组名是该数组首元素的地址,作为实际参数的数组名要求形式参 数是一个与之匹配的指针。只有在这种情况下,C才会把int ar[]和int * ar解 释成一样。也就是说,ar是指向int的指针。由于函数原型可以省略参数名, 所以下面4种原型都是等价的:
int sum(int *ar, int n);
int sum(int *, int);
int sum(int ar[], int n);
int sum(int [], int);
但是,在函数定义中不能省略参数名。下面两种形式的函数定义等价:
示例:
使用 sum()函数。该程序打印原始数 组的大小和表示该数组的函数形参的大小
#include <stdio.h>
#define SIZE 10
int sum(int ar[], int n);
int main(void)
{
int marbles[SIZE] = { 20, 10, 5, 39, 4, 16, 19, 26,
31, 20 };
long answer;
answer = sum(marbles, SIZE);
printf("The total number of marbles is %ld.\n", answer);
printf("The size of marbles is %zd bytes.\n",
sizeof marbles);
return 0;
}
int sum(int ar[], int n) // 这个数组的大小是?
{
int i;
int total = 0;
for (i = 0; i < n; i++)
total += ar[i];
printf("The size of ar is %zd bytes.\n", sizeof ar);
return total;
}
输出:
The size of ar is 8 bytes. //指向数组第一个元素的指针大小
The total number of marbles is 190.
The size of marbles is 40 bytes.
注意,marbles的大小是40字节。这没问题,因为marbles内含10个int类 型的值,每个值占4字节,所以整个marbles的大小是40字节。但是,ar才8字 节。这是因为ar并不是数组本身,它是一个指向 marbles 数组首元素的指 针。我们的系统中用 8 字节储存地址,所以指针变量的大小是 8字节(其他 系统中地址的大小可能不是8字节)。简而言之,在程序清单10.10中, marbles是一个数组, ar是一个指向marbles数组首元素的指针,利用C中数组 和指针的特殊关系,可以用数组表示法来表示指针ar。
10.4.1 使用指针形参
函数要处理数组必须知道何时开始、何时结束。
两种方法…… 第一种,传一个指针形参传一个整数形参,指针形参标志开始,整数形参标志数组大小
第二种传入两个指针形参一个标志数组开始,一个标志数组结束
示例演示第二种方法,同时该示例表明指针形参是变量,这意味着可以用索引表明访问数组中的哪一个元素
#include <stdio.h>
#define SIZE 10
int sump(int * start, int * end);
int main(void)
{
int marbles[SIZE] = { 20, 10, 5, 39, 4, 16, 19, 26,
31, 20 };
long answer;
answer = sump(marbles, marbles + SIZE);//重点
printf("The total number of marbles is %ld.\n", answer);
return 0;
}
/* 使用指针算法 */
int sump(int * start, int * end)
{
int total = 0;
while (start < end)
{
total += *start; // 把数组元素的值加起来
start++; // 让指针指向下一个元素
}
return total;
}
指针start开始指向marbles数组的首元素,所以赋值表达式total += start 把首元素(20)加给total。然后,表达式start++递增指针变量start,使其指 向数组的下一个元素。**因为start是指向int的指针,start递增1相当于其值递增 int类型的大小。 ***
标记重点
注意,sump()函数用另一种方法结束加法循环。sum()函数把元素的个数 作为第2参数,并把该参数作为循环测试的一部分:
for( i = 0; i < n; i++)
而sump()函数则使用第2个指针来结束循环:
while (start < end)
因为while循环的测试条件是一个不相等的关系,所以循环最后处理的 一个元素是end所指向位置的前一个元素。这意味着end指向的位置实际上在 数组最后一个元素的后面。C保证在给数组分配空间时,指向数组后面第一 个位置的指针仍是有效的指针。这使得 while循环的测试条件是有效的,因为 start在循环中最后的值是end[1]。注意,使用这种“越界”指针的函数调用 更为简洁:
answer = sump(marbles, marbles + SIZE);
因为下标从0开始,所以marbles + SIZE指向数组末尾的下一个位置。如 果end指向数组的最后一个元素而不是数组末尾的下一个位置,则必须使用 下面的代码:
answer = sump(marbles, marbles + SIZE - 1);
这种写法既不简洁也不好记,很容易导致编程错误。顺带一提,虽然C 保证了marbles + SIZE有效,但是对marbles[SIZE](即储存在该位置上的 值)未作任何保证,所以程序不能访问该位置。
还可以把循环体压缩成一行代码: total += *start++;
一元运算符和++的优先级相同,但结合律是从右往左,所以start++先 求值,然后才是start。也就是说,指针start先递增后指向。使用后缀形式 (即start++而不是++start)意味着先把指针指向位置上的值加到total上,然 后再递增指针。如果使用*++start,顺序则反过来,先递增指针,再使用指 针指向位置上的值。如果使用(*start)++,则先使用start指向的值,再递增该 值,而不是递增指针。
10.4.2 指针表示法和数组表示法
处理数组的函数实际上用指针作为参数,但是在编写 这样的函数时,可以选择是使用数组表示法还是指针表示法。
使用数组表示法,让函数是处理数组的这一意图更加明显。
至于C语言,ar[i]和*(ar+1)这两个表达式都是等价的。无论ar是数组名 还是指针变量,这两个表达式都没问题。但是,只有当ar是指针变量时,才 能使用ar++这样的表达式。
指针表示法(尤其与递增运算符一起使用时)更接近机器语言,因此一 些编译器在编译时能生成效率更高的代码。
10.5 指针操作
基本用法
***赋值:可以把地址赋给指针。例如,用数组名、带地址运算符(&)的 变量名、另一个指针进行赋值。在该例中,把urn数组的首地址赋给了ptr1, 该地址的编号恰好是0x7fff5fbff8d0。变量ptr2获得数组urn的第3个元素 (urn[2])的地址。注意,地址应该和指针类型兼容。也就是说,不能把 double类型的地址赋给指向int的指针,至少要避免不明智的类型转换。 C99/C11已经强制不允许这样做。 ***
**解引用:运算符给出指针指向地址上储存的值。因此,*ptr1的初值是 100,该值储存在编号为0x7fff5fbff8d0的地址上。 ***
- **取址:和所有变量一样,指针变量也有自己的地址和值。对指针而言, &运算符给出指针本身的地址。本例中,ptr1 储存在内存编号为 0x7fff5fbff8c8 的地址上,该存储单元储存的内容是0x7fff5fbff8d0,即urn的地 址。因此&ptr1是指向ptr1的指针,而ptr1是指向utn[0]的指针。 ***
指针与整数相加:可以使用+运算符把指针与整数相加,或整数与指针 相加。无论哪种情况,整数都会和指针所指向类型的大小(以字节为单位) 相乘,然后把结果与初始地址相加。因此ptr1 +4与&urn[4]等价。如果相加 的结果超出了初始指针指向的数组范围,计算结果则是未定义的。除非正好 超过数组末尾第一个位置,C保证该指针有效。
- *递增指针:递增指向数组元素的指针可以让该指针移动至数组的下一个 元素。因此,ptr1++相当于把ptr1的值加上4(我们的系统中int为4字节), ptr1指向urn[1](见图10.4,该图中使用了简化的地址)。现在ptr1的值是 0x7fff5fbff8d4(数组的下一个元素的地址),ptr的值为200(即urn[1]的 值)。注意,ptr1本身的地址仍是 0x7fff5fbff8c8。毕竟,变量不会因为值发 生变化就移动位置。 ***
指针减去一个整数:可以使用-运算符从一个指针中减去一个整数。指 针必须是第1个运算对象,整数是第 2 个运算对象。该整数将乘以指针指向 类型的大小(以字节为单位),然后用初始地址减去乘积。所以ptr3 - 2与 &urn[2]等价,因为ptr3指向的是&arn[4]。如果相减的结果超出了初始指针所 指向数组的范围,计算结果则是未定义的。除非正好超过数组末尾第一个位 置,C保证该指针有效。
***递减指针:当然,除了递增指针还可以递减指针。在本例中,递减ptr3 使其指向数组的第2个元素而不是第3个元素。前缀或后缀的递增和递减运算 符都可以使用。注意,在重置ptr1和ptr2前,它们都指向相同的元素urn[1]。 ***
***指针求差:可以计算两个指针的差值。通常,求差的两个指针分别指向 同一个数组的不同元素,通过计算求出两元素之间的距离。差值的单位与数 组类型的单位相同。例如,程序清单10.13的输出中,ptr2 - ptr1得2,意思是 这两个指针所指向的两个元素相隔两个int,而不是2字节。只要两个指针都 指向相同的数组(或者其中一个指针指向数组后面的第 1 个地址),C 都能 保证相减运算有效。如果指向两个不同数组的指针进行求差运算可能会得出 一个值,或者导致运行时错误。 ***
比较:使用关系运算符可以比较两个指针的值,前提是两个指针都指向相同类型的对象。*
注意,这里的减法有两种。可以用一个指针减去另一个指针得到一个整 数,或者用一个指针减去一个整数得到另一个指针。*
***在递增或递减指针时还要注意一些问题。编译器不会检查指针是否仍指 向数组元素。C 只能保证指向数组任意元素的指针和指向数组后面第 1 个位 置的指针有效。但是,如果递增或递减一个指针后超出了这个范围,则是未 定义的。另外,可以解引用指向数组任意元素的指针。但是,即使指针指向 数组后面一个位置是有效的,也能解引用这样的越界指针。 ***
- **创建一个指针 时,系统只分配了储存指针本身的内存,并未分配储存数据的内存。因此, 在使用指针之前,必须先用已分配的地址初始化它。 ***
实际操作
#include<stdio.h>
void swape(int *ap,int *bp); //这里是用指针做一些数据交换
int main()
{
int a=5;
int b=6;
printf("%d %d",a,b);
getchar();
swape(&a,&b);
printf("%d %d",a,b);
}
void swape(int *ap,int *bp)
{
int t=*ap;
*ap=*bp;
*bp=t;
}
int main() //这里可以简单的理解为*代表获取的数值 &表示获取的地址
{
int a=5;
int b=6;
int *p=a+1;
printf("%p %p %d\n",&a,&b,p);
}
void quezhi(int a[],int len,int *min,int *max);
int main()
{
int a[]={1,2,3,4,5,6,7,8,9,11,22,33,44,98,66,77,88,55};
int min,max;
int b=sizeof(a)/sizeof(a[0]); //这里面的sizeofa[]里面可以填范围之内的,因为这东西就是一个代表字节为长度的,同一个数组一个数占的位一样的
quezhi(a,sizeof(a)/sizeof(a[0]),&min,&max);
printf("%d %d %d\n",min,max,b);
}
void quezhi(int a[],int len,int *min,int *max) //这个还是指针的基本用法,找出最大的值和最小的值
{
int t;
*min=*max=a[0];
for (int num=1;num<len;num++)
{
if (a[num]<*min)
{
*min=a[num];
/* code */
}
if (a[num]>*max)
{
*max=a[num];//因为这里是循环所以会挑出最大的值
/* code */
}
}
}
int jisuan(int a,int b,int *p);
int main()//函数返回运算的状态(是否成功),运算的结果通过指针返回
{
int a,b,c;
scanf("%d %d",&a,&b);
if( jisuan(a,b,&c) )
{
printf("%d/%d=%d",a,b,c);
}
}
int jisuan(int a,int b,int *p)
{
int ret=1;
if (b=0)
{
ret=0;
printf("错误!!");
/* code */
}
else {
*p=a/b;//这里有问题】
}
return ret;
}
//用指针可以干什么
//1.需要传入较大的值时用作参数,比如穿数组
//2.传入数组后对数组进行操作,*p++
//3.函数返回不止一个结果 需要用函数来修改不止一个变量
//4.动态内存的申请
作业:
8.使用编程练习2中的拷贝函数,把一个内含7个元素的数组中第3~第5 个元素拷贝至内含3个元素的数组中。该函数本身不需要修改,只需要选择 合适的实际参数(实际参数不需要是数组名和数组大小,只需要是数组元素 的地址和待处理元素的个数)。
#include<stdio.h>
int copy(int *a,int *b);
int main()
{
int a[6]={1,2,3,4,5,6,7};
int b[2];
copy(a,b);
printf("拷贝完成\n");
printf("3 %d \n",b[0]);
printf("3 %d \n",b[1]);
printf("3 %d \n",b[2]);
for (int i=0;i<3;i++)
{
printf("%d ",b[i]);
}
return 0;
}
int copy(int *a,int *b)
{
*b=*(a+2);
*(b+1)=*(a+3);
*(b+2)=*(a+4);
}
9.编写一个程序,初始化一个double类型的3×5二维数组,使用一个处理 变长数组的函数将其拷贝至另一个二维数组中。还要编写一个以变长数组为 形参的函数以显示两个数组的内容。这两个函数应该能处理任意N×M数组 (如果编译器不支持变长数组,就使用传统C函数处理N×5的数组)。
#include <stdio.h>
#define N 3
#define M 5
void show(int n, int m, const double x[n][m]);
void copy(int n, int m, const double a[n][m], double b[n][m]);
int main(void)
{
double a[N][M] =
{
{1.0,2.0,3.0,4.0,5.0},
{6.0,7.0,8.0,9.0,10.0},
{11.0,12.0,13.0,14.0,15.0}
};
double b[N][M] = {0.0};
copy_array(N, M, a, b);
printf("复制后b是\n");
show_array(N, M, b);
return 0;
}
void show_array(int n, int m, const double x[n][m])
{
int i, j;
for (i = 0; i < n; i++)
{
for (j = 0; j < m; j++)
{
printf("%-5g", x[i][j]);
}
putchar('\n');
}
return;
}
void copy_array(int n, int m, const double a[n][m], double b[n][m])
{
int i, j;
for (i = 0; i < n; i++)
{
for (j = 0; j < m; j++)
{
b[i][j] = a[i][j];
}
}
return;
}



